文章目录
- 对比学习
- 数据增强
- 基于特征的增强
- 基于结构的增强
- 基于采样的增强
- 自适应的增强
- 代理任务
-
- 目标函数
- 参考
CSDN排版太垃圾了,点此连接去知乎看吧!!!!!
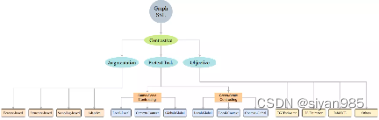
自监督学习(SSL)的最新进展为减少对标签的过度依赖,实现在大量无标注数据上的训练提供了新的见解。自监督学习的主要目标是通过精心设计的代理任务,从丰富的无标签数据中学习可迁移的知识,然后将学到的知识迁移到具有特定监督信号的下游任务中。Graph SSL方法分为三类:对比式的、生成式的和预测式的。

- 比式方法:对不同的增广t1(.)和t2(.)产生的视图进行对比学习,将数据-数据对(inter-data)之间的共性和差异信息作为监督信号。
生成式方法:关注图数据内部(intra-data)的信息,一般基于特征/结构重构等代理任务,利用图本身的特征和结构作为监督信号。
预测式方法:通过一些简单的统计分析或专家知识self-generate伪标签,然后根据生成的伪标签设计基于预测的代理任务来处理数据-标签(data-label)关系。
对比学习
基于互信息最大化的对比学习方法层出不穷,对比式学习的自监督方法最为大家关注。自监督对比式学习的三个主要模块是数据增广、代理任务设计和对比目标,现有工作的贡献基本上可以归纳为在这三个模块上的创新。
对比学习一般通过各种的数据增广方式(甚至是它们的组合)为数据集中的每个实例生成多个视图。从同一实例中生成的两个视图通常被认为是一个正样本对,而从不同实例中生成的两个视图则被认为是一个负样本对。对比学习的目标是通过最大化正样本的一致性,让负样本之间距离远离。其中,样本的一致性信息是通过互信息衡量的。
对于给定的图g=(A,X),K个不同的增强变换得到K个视图(Ai, Xi)
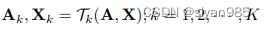
然后为每个视图生成对应的表示hi(可以是结点表示,子图表示,图级表示)
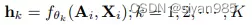
对比学习的目标是最大化同一实体在两个视图上的互信息即
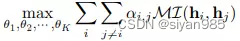
数据增强
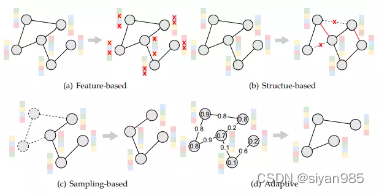
由于图数据的非欧特性,很难将为图像领域的数据增广策略直接应用于图数据领域。在这里,我们把针对图数据的数据增广策略分为以下四类:基于特征的增广、基于结构的增广、基于采样的增广和自适应的增广。
- 基于特征增强的方法一般随机或者手动的遮盖一小部分结点或者边的属性。
基于结构增强的方法一般随机或者手动从原图中添加或者删除一小部分边。比如边扰动,结点插入,边扩散等。
基于采样的增强方法从原图中按照一定规则采样结点和对应的连边。比如均匀采样,ego-net采样,随机游走采样,重要性采样和基于知识的采样。
基于自适应的采样方法采用注意力机制或者基于梯度的方法根据注意力权重或者梯度规模进行自适应采样。
基于特征的增强
对于给定的输入图G=(A,X),基于特征的增强只对结点的特征矩阵X或者边的特征矩阵Xe进行增强。

**属性遮掩(Attribute Masking)**通过掩码的方式随机遮盖一部分结点或者边的特征。
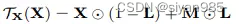
其中,L是掩码位置矩阵,M为掩码值矩阵。Lij取值为0或1,Mij为遮掩后对应位置赋的值。
**属性搅乱(Attribute Shuffling)**对结点特征矩阵进行行级混洗。增强后的图和原图拥有相同的结点集但是结点的上下文环境不再相同。
基于结构的增强
对于给定的输入图G=(A,X),基于结构的增强只对邻接矩阵进行增强。

**边扰动(Edge Perturbation)**通过随机添加或删除一定比例的边来扰乱结构连接
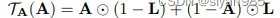
同特征增强,L为位置矩阵。
**边扩散(Edge Diffusion)**使用一般的边扩散过程为原始的图结构生成不同的拓扑结构视图。

其中S为过渡矩阵,θ的和为1。常见的两个实例为personalized pagerank和heat kernel。
personalized pagerank
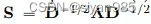
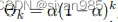
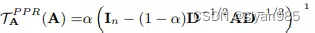
α为随机游走中的传输概率
heat kernel
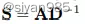
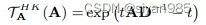
t为扩散时间
**结点插入(Node Insertion)**是在原结点集中添加一些结点并在新加入的结点和原始结点之间添加一些边。
基于采样的增强
给定一个输入图G=(A,X),基于采样的增强同时对邻接矩阵A和特征矩阵X进行增强。
Uniform Sampling均匀地从结点集中采样给定数量的结点,然后移除剩余结点
Ego-net Sampling每次在结点i周围的L跳邻居内采样
Random Walk Sampling从起始节点i开始在图上进行随机游走。游走以与边权重成正比的概率迭代地前往其邻域。此外,在每一步以正概率α返回到起始节点i。最后,被访问的节点被纳入一个节点子集中。
Importance Sampling对于给定结点i,按照其邻居的重要性进行采样一个子图.重要性得分矩阵记作
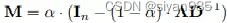
Knowledge Sampling引入领域的先验知识进行采样.
自适应的增强
自适应的增强是采用注意力机制或者梯度来引导结点或边的选择的.
Attention-based基于注意力的方法为结点或边定义重要性权重,然后按照权重进行增强.保留重要的结构和特征信息,对不重要的部分进行扰动.例如GCA中根据结点的中心性计算权重,按照重要性扰动边和结点.
Gradient-based不同于GRACE中简单的均匀边添加和删除,GROC按照梯度自适应进行增强.具体而言,首先构建两个随机的视图,然后计算两个视图间的对比损失.对于一个给定的结点vi,定义一个边的删除候选集

和边的插入候选集
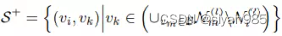
B为一个batch,反向传播损失计算各个边的梯度值.从待删除边集中删除一部分最小梯度值得边,给插入候选集中插入一部分最大梯度值的边
代理任务
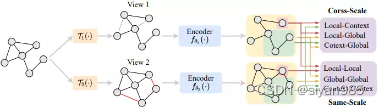
对比学习的目的是最大化正样本对之间的一致性。视图的尺度可能是局部的,上下文的或者全局的,对应的图中结点级,子图级和图级别的信息。对比学习可以在相同或者不同尺度上进行对比。
同尺度对比
Global-Global
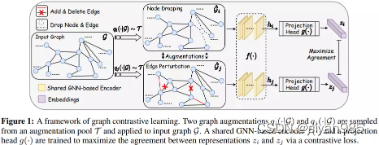
GraphCL是典型的全局-全局对比模式,采用上述任何一种增强方式生成视图g’,然后判断生成的视图是否与原始图是同一张图。具体来说就是使用同一个编码器在原始图和增强的视图上进行编码得到图级别的表示,最终学习目标是
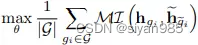
Context-Context
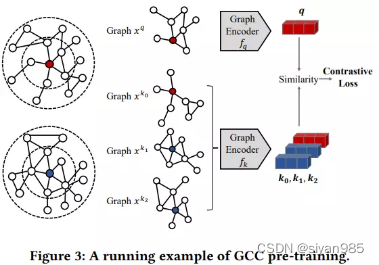
GCC是在多个图之间捕获一般的图拓扑属性。首先通过随机游走采样多个子图并编码为图级别表示h。如果图q和k采样于同一张图,则为正样本对,否则为负样本对。

I表示第i个k图和q图是否采样于同一张图
Local-Local

GRACE关注于结点级别的对比。对于增强的两张视图,采用共享的编码器生成结点的表示。对于每个正样本对儿的目标函数为
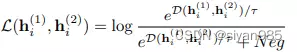

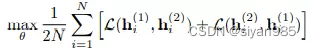
GCA和GROC都采用和GRACE相同的框架学习.

GMI通过直接对比结点的输入特征和对应的结点表示来学习的。
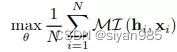
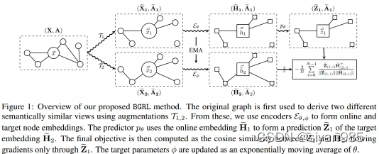
BGRL不需要负采样,在增强的两个视图上使用两个编码器学习结点表示。然后使用一个结点级的映射层g()得到Z1 = g(H1),最终的学习目标为
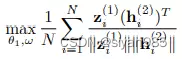
编码器2的参数θ2通过指数移动平均EMA得到。
跨尺度对比
Local-Global
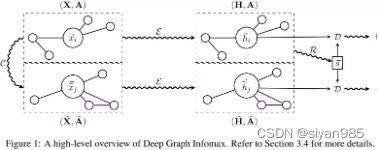
DGI通过生成一个视图后并计算对应的图级别表示,然后最大化与原始图上的结点的表示之间的互信息。
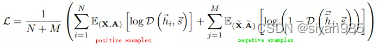
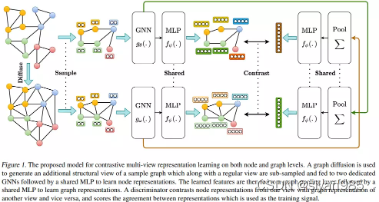
MVGRL通过最大化不同视图间结点和图的表示的互信息来学习。
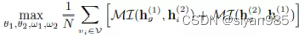
Local-Context
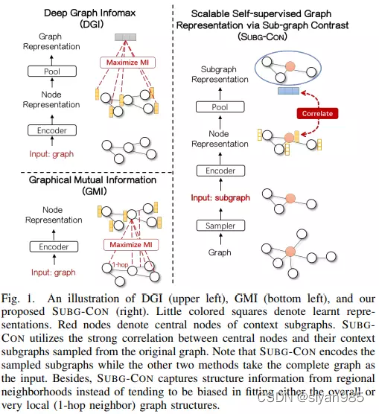

SUBG-CON利用锚点和周围子图之间的强关联性捕获上下文结构信息。SUBG-CON首先采样一组锚点集合,然后采样对应的子图集合。使用一个共享的图编码器和图聚合器得到结点表示和图级别表示。最终目标函数为
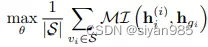
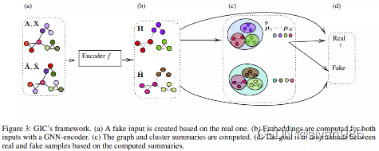
GIC在DGI的基础上还最大化了结点和对应簇的嵌入之间的互信息。使用无监督聚类算法将结点分为K个簇,使用每个簇中结点表示的平均来表示簇中心的表示。为每个结点vi计算一个簇嵌入zi即使用簇中心嵌入的加权求和计算。其中权重rik表示结点i分到簇k中的概率。最后最大化结点和对应簇嵌入之间的互信息

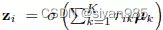

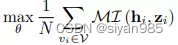
Context-Global
MICRO-Graph,子图级的对比难点在于采样语义信息的子图。motif可以很好的辅助采样。首先在得到的两组视图中的结点表示上采样K个motif-like子图,然后使用readout函数得到图级别和子图级别的表示。
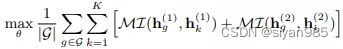
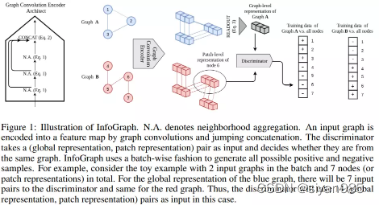
InfoGraph目的在于在整个图级别上学习嵌入。首先生成一个视图,然后采用一个共享的L层图编码器来计算每一层的结点表示。通过连接每层的结点表示来得到综合的结点表示。然后使用readout函数得到图级别的表示,目标函数如下,其中负样本来自增强的视图中。
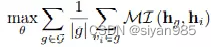
目标函数
对比学习优化的主要方式是把两个视图的表示视作随机变量,然后最大化他们之间的互信息
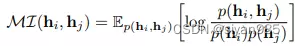
为了高效计算互信息,三种互信息的下界形式被推到出来了。最大化互信息通过间接最大化他们的下界得到。
Donsker-Varadhan Estimator是一种互信息的下界形式定义如下,D为判别函数,计算两个表示的一致性得分

Jensen-Shannon Estimator使用JS散度来替换原始的KL散度,更高效些。
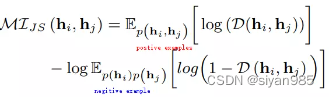
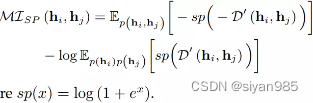
InfoNCE Estimator是最受欢迎的下界形式,K是由一个独立同分布的N个随机变量组成。

以图分类为例,一个batch size为N+1的mini-batch B的Info NCE计算如下
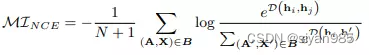
hi和hj是来自同一视图的正样本对,h’为另一视图生成的负样本
Triplet Margin Loss对于对比学习,最大化互信息不是必须的。Triplet Margin Loss可以优化对比学习但不是基于互信息的对比目标函数。
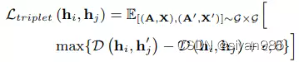
Triplet Margin Loss不直接最小化负样本对D(hi, hj’)之间的一致性,只确保负样本对之间的一致性小于正样本对之间的一致性。也就是说,如果负样本之间足够远离,没必要进一步减少一致性,应把重点放在较难分别的样本上。
quadruplet loss在Triplet Margin Loss的基础上进一步考虑类间约束
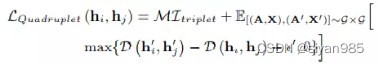
quadruplet loss使用基于锚点的采样策略并且负采样更加随机,可以帮助识别类间边界。
RankMI Loss quadruplet loss和Triplet Margin Loss忽略了互信息的下界,RankMI无缝地把信息论方法整合到了表示学习和最大化相同类别样本互信息中。
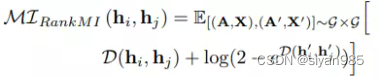
参考
- https://mp.weixin.qq.com/s/xJQLb5xbFPvL211YnO9ivw
- Self-supervised Learning on Graphs: Contrastive, Generative,or Predictive
- https://zhuanlan.zhihu.com/p/277660074
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)