1、什么是场景(Scene)
场景作为电影讲故事的关键单元,包含了演员的复杂活动及其在物理位置上的互动。识别场景的组成和语义是视觉理解复杂长视频(如电影、电视剧、娱乐节目和综艺节目)的关键一步。与传统视觉问题(如动作识别)中研究的视频相比,电影中的场景通常包含更丰富的时间结构和更复杂的语义信息。
场景变化在电影的叙事中起着重要的作用,举个例子:当我们看下面这些图中的任何一个镜头时,例如第二个镜头中的女人,我们并不能判断出当前的事件是什么。只有当我们考虑到这个场景中的所有镜头,我们才能认识到这是个什么事件:“这个女人在邀请一对情侣和乐队跳舞。”

1.1 场景的定义:
场景是一个基于情节的语义单元,其中某一活动发生在某一组角色之间。场景由单个或多个连续的镜头构成,虽然一个场景经常发生在一个固定的地方,但也有可能一个场景在多个地方之间不断穿梭,例如在电影中的打斗场景中,角色从室内移动到室外。
1.2 场景示例:
下图底部的蓝线对应于整个电影时间线,其中深蓝色和浅蓝色区域代表不同的场景。在场景10中,角色在两个不同的地方打电话,因此需要对这个场景有语义上的理解,以防止将它们分成不同的场景。在场景11中,内容变得更加复杂,因为这个直播场景涉及三个以上的地方和角色组。在这种情况下,只有视觉提示可能会无法正确划分出来,因此其他方面比如音频提示变得至关重要。

1.3 区分场景(scene)、镜头(spot)、帧(frame)
场景和镜头本质上是不同的。一个镜头是由一个不间断的运行一段时间的摄像机拍摄的,因此在视觉上是连续的;而场景是更高级别的语义单元。一个场景由一系列镜头组成,呈现故事语义连贯的部分(比如上文的第一组镜头组成了一个场景)。使用现有工具基于简单的视觉线索将电影容易地划分成镜头,但是识别构成场景的那些镜头子序列并不容易,因为它需要语义理解,以便发现语义一致但视觉上不同的那些镜头之间的关联。
总结一下:(1)帧:视频中单幅的静态图片;(2)镜头:视频中像素差异不大的连续帧集;(3)场景:视频中语义差异不大的连续帧集。
2、 LGSS:一种局部到全局的多模态电影场景分割方法(A Local-to-Global Approach to Multi-modal Movie Scene Segmentation)
LGSS采用了一种基于镜头的方法,认为场景边界必须是所有镜头边界的子集,这种方法基于这样一种理解:场景分割可以被公式化为二元分类问题,即确定镜头边界是否是场景边。因此先进行镜头切割,再通过地点,人物,动作和音频对镜头进行分类(是否为场景边界)
LGSS 框架通过三个阶段执行场景分割:
(1)从多个方面提取镜头表示(地点,人物,动作和音频)
(2)基于集成的信息进行局部预测
(3)通过解决全局优化问题来优化镜头的分组。
局部到全局的场景分割:
局部到全局的场景分割可以解决分割场景需要识别多个语义方面和使用复杂的时间信息的问题。基于镜头表示si,LGSS 设计了一个三层模型来整合不同层次的上下文信息,即剪辑级(B),、片段级(T)和电影级(G)。模型给出了一系列预测[o1,…,on-1],其中 oi∑{ 0,1} 表示第 i 个和第 (i + 1)个镜头之间的边界是否是场景边界。
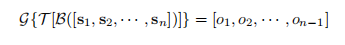
下面介绍 LGSS 如何获取 si,即如何用多个语义元素表示镜头,然后说明模型的三个层次的细节,即 B、T 和 G。
总体框架如下图所示:

1、使用语义元素进行镜头表示
电影是一种典型的多模态数据,包含不同的高级语义元素。场景是一系列镜头共享一些共同元素的地方,例如地点、演员等。因此,考虑这些相关的语义元素对于场景划分是很重要的。在 LGSS 框架中,镜头由四个在场景构成中起重要作用的元素来表示:地点、演员、动作和音频。
获得每个镜头 si 语义特征的过程:
1)使用 ResNet50 对 Places 数据集的关键帧图像进行预训练来获得位置特征
2)使用 Faster-RCNN 在CIM数据集上预训练来检测演员实例,并使用ResNet50 在 PIPA 数据集上预训练提取演员的人物特征
3)使用 TSN 在 AVA 数据集上进行预训练以获得动作特征
4)使用 NaverNet 在 AVA-ActiveSpeaker 数据集上进行预训练来分离台词和背景音,使用短时间傅里叶变换分别在16khz采样率和512个窗口信号长度的镜头中获得它们的特征,并将它们连接起来,以获得音频特征
2、剪辑级别的镜头边界表示
LGSS 提出了一个边界网络(BNet)来模拟镜头边界,BNet(记为B)以2wb 个镜头的电影剪辑作为输入,输出一个边界表示为bi 。基于直觉,边界表示应该捕捉前后镜头之间的差异和关系,BNet 由两个部分组成,即 Bd 和 Br 。Bd由两个时间卷积层建模,每个层分别嵌入边界前后的镜头,通过内积运算来计算它们的差异;Br 的目的是捕捉镜头的关系,它是通过一个遵循最大池的时间卷积层来实现。
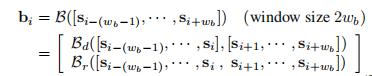
3、段级粗预测
在得到每个镜头边界 bi 的表示后,问题变成了基于序列 [b1,···,bn−1] 预测二进制标签序列 [o1,o2,···,on−1],可以通过 sequence-to-sequence 模型来解决这个问题。然而,镜头的数量 n 通常大于1000,现有的序列模型很难存储如此长的序列。LGSS 设计了一个片段级的模型,基于一个由 wt 个镜头(wt << n)组成的电影片段来预测一个粗糙的结果。使用序列模型 T,例如Bi-LSTM,使用步幅为 wt/2 的镜头来预测一个粗评分序列[p1,···,pn−1],这里的 pi∈[0,1] 是一个镜头边界成为一个场景边界的概率。
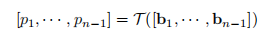
然后通过使用阈值τ对pi进行二值化,得到一个对 (oi)'∈{0,1} 的粗预测,它表明第 i 个边界是否为场景边界
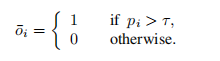
4、电影级别上的全局最优分组
片段级模型得到的分割结果是不够好的,因为它只考虑了 wt个 镜头上的局部信息,而忽略了整个电影上的全局上下文信息。为了获取到全局的构造,LGSS 提出了一个全局最优模型G来考虑电影水平的上下文。模型把镜头表示 si 和粗预测 (oi)’ 作为输入,oi 的最终结果如下: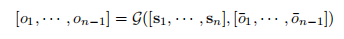
3、电影场景数据集:
为了促进场景理解,构造了数据集MovieScenes,其中包含了21K个场景,是通过对150部电影中的270K个镜头分组得出的。与其他现有的数据集相比,MovieScenes规模巨大,镜头数量多,总持续时间长,涵盖了更广泛的数据源,拥有各种场景。涵盖了种类繁多的流派,包括戏剧、惊悚片、动作片,使得数据集更加全面和通用。带注释的场景长度从10s到120s不等,提供了较大的可变性。
总结
实验结果表明 LGSS 框架比现有方法具有更好的性能,位置、演员、动作和音频都是帮助场景分割的有用信息,且基于局部预测和全局优化的模型对场景分割有很好的效果。
参考文献:https://arxiv.org/pdf/2004.02678v3.pdf
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)