网址链接
在很多多输入任务中,例如 visual question-answering (image + language), instruction-following (video + language), class-conditional image generation (image + class label), style transfer (style image + context image)等,需要根据多种输入特征来进行预测。
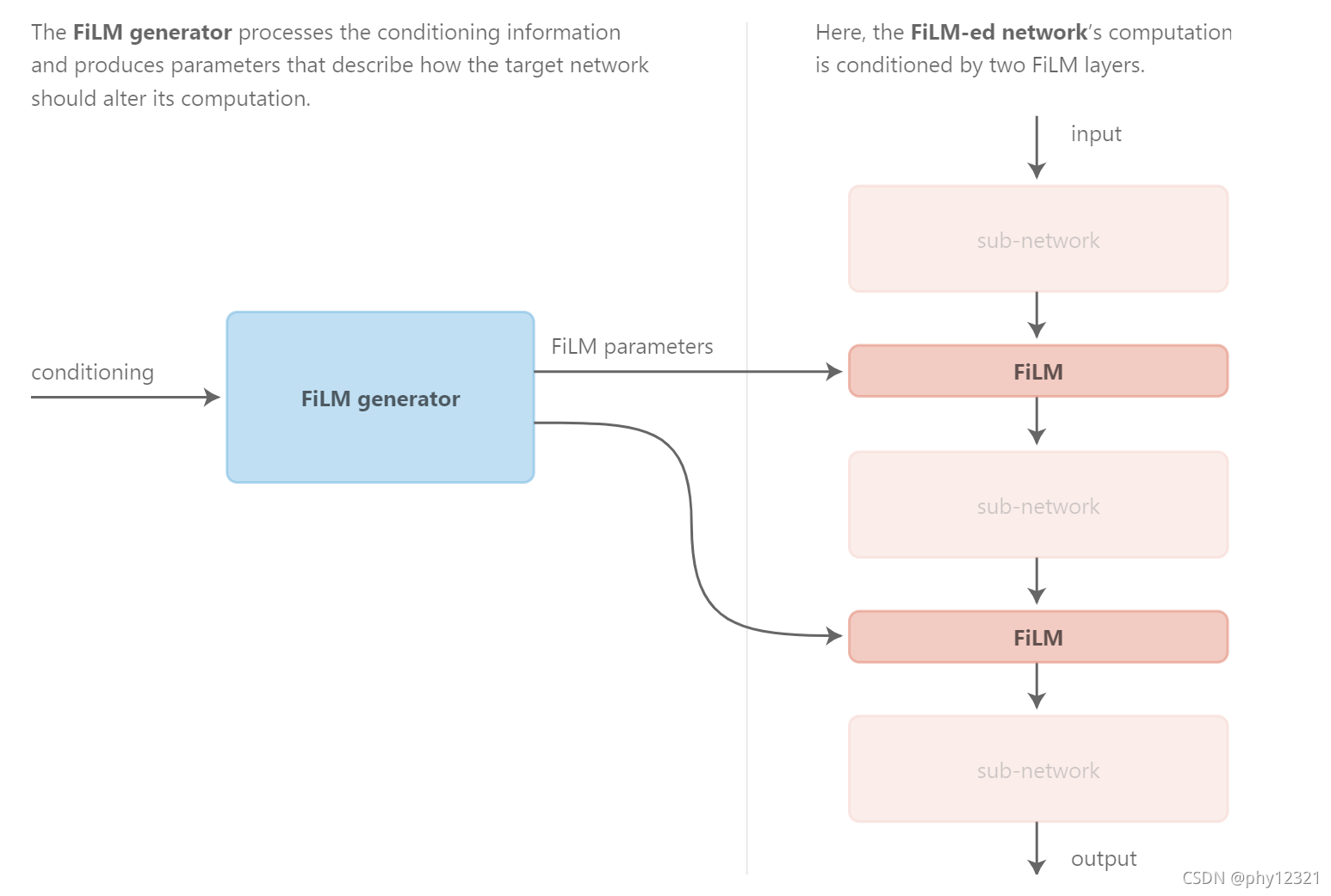
本文主要介绍一种可以嵌入到CNN模型中的通用网络层,即conditioning layer, 用于多输入任务。例如,对于分类+回归的任务,有可能回归任务是基于分类结果的输出,分类结果不同,回归出来的值也不一样。conditioning layer 不仅能够和传统卷积层一样以特征图为输入,还可以用分类结果的输出作为出入,来指导回归结果。
现有方法
-
concatenation-based conditioning
即将输入的数据和条件信息进行concatenate,然后输入到网络中。这种做法的问题在于,网络有可能不是在当前层需要该条件信息,而是在最后几层才需要条件信息。这要求网络的前几层能够保有原来条件信息。
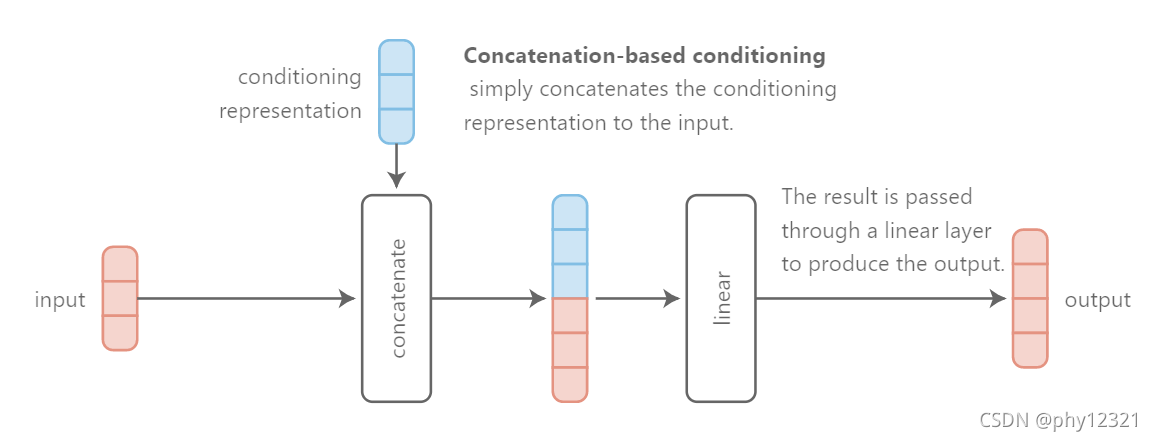
-
conditional biasing
先对条件信息进行处理,然后将得到的条件信息编码的vector作为一个bais, 与输入数据相加, 得到输出。
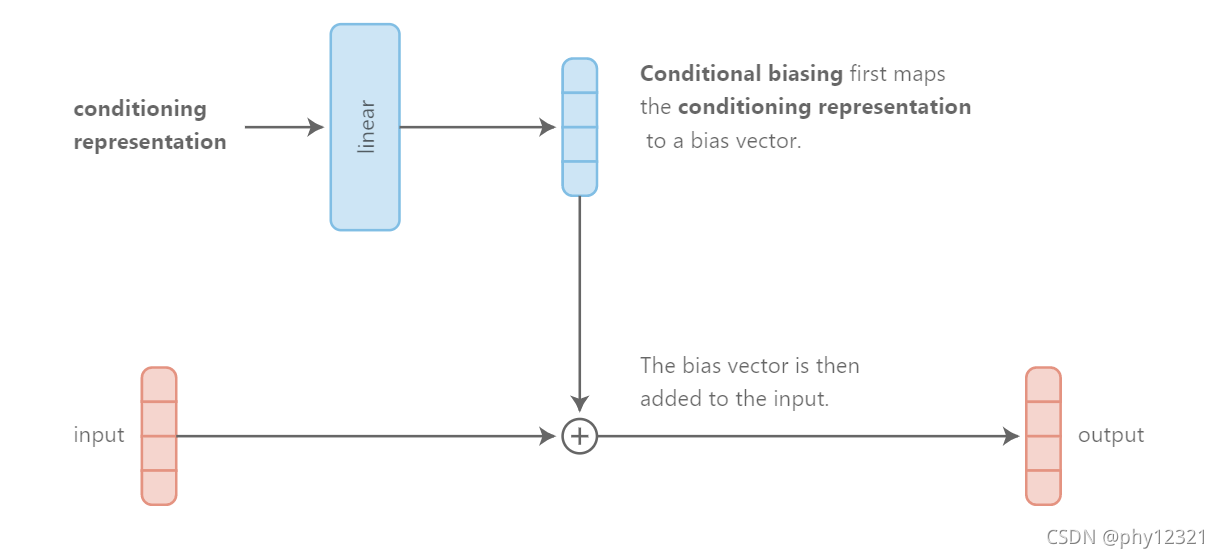
实际上,这种方法可以理解为concatenation-based conditioning的另一种实现方式。
-
conditional scaling
前一种方法是将条件信息编码的特征加在了输入数据上,该方法则用乘法代替。
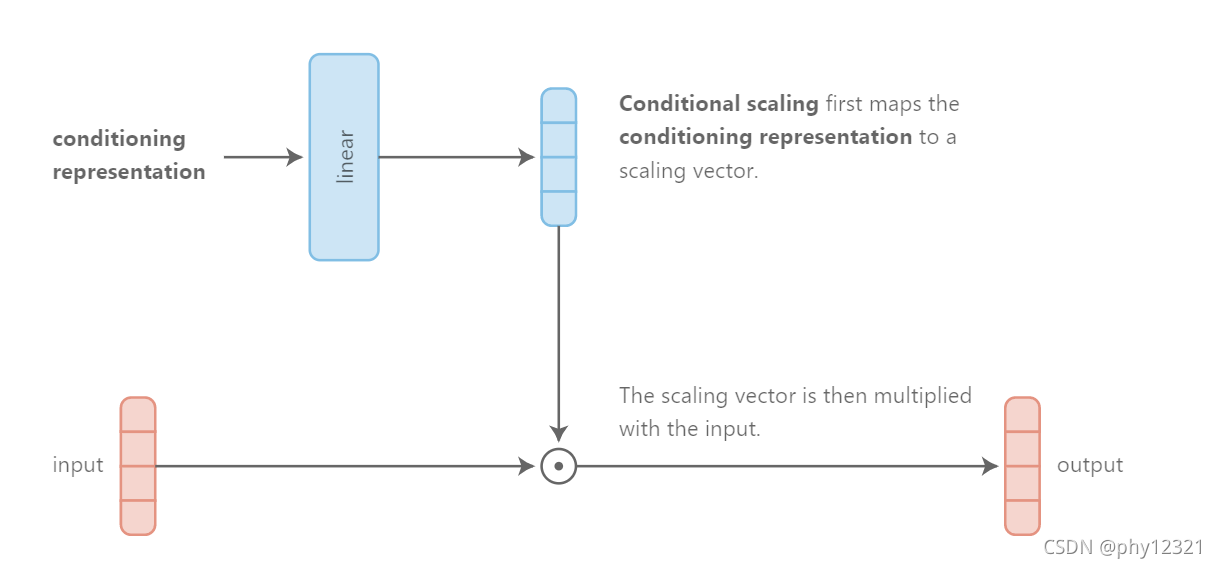
对于加性和乘性操作的优劣论述 :
- 支持加性交互的一个论点是,对于不太强烈依赖于两个输入的联合值的应用场景,如特征聚合或特征检测(即,检查两个输入中是否存在特征),加性交互更为自然。
- 支持乘性交互的一个论点是,它们有助于学习输入之间的关系,因为这些交互自然会识别“匹配”:将符号一致的元素相乘会产生比不一致的元素相乘更大的值。这就是为什么经常使用点积来确定两个向量的相似程度。
因此较好的做法是同时采取乘法和加法操作,这也就是本文所提出的conditioning layer中所用到的操作,Feature-wise Linear Modulation, FiLM.
Feature-wise Linear Modulation
介绍链接
通过对多输入任务中的每个特征进行线性调制,达到对不同输入得到不同输出的目的。
对
输
入
特
征
的
线
性
调
制
过
程
:
New
F
i
,
c
=
(
V
i
,
c
∗
F
i
,
c
)
+
β
i
,
c
这
里
的
V
和
β
是
单
独
需
要
一
个
网
络
(
F
i
L
M
g
e
n
e
r
a
t
o
r
)
来
进
行
预
测
的
。
对输入特征的线性调制过程:\text { New } F_{i, c}=\left(V_{i, c}{ }^{*} F_{i, c}\right)+\beta_{i, c}\\ 这里的V和\beta是单独需要一个网络( FiLM \ \ generator)来进行预测的。
对输入特征的线性调制过程: New Fi,c=(Vi,c∗Fi,c)+βi,c这里的V和β是单独需要一个网络(FiLM generator)来进行预测的。
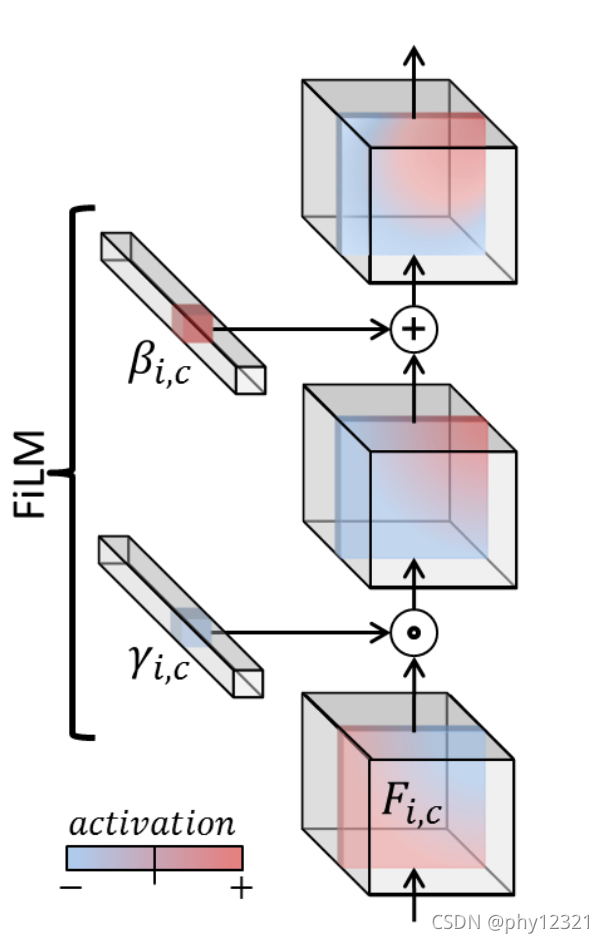
当然,可以使用更复杂的操作(而不是仿射变换),但FiLM通常会在有效性和效率之间达成令人满意的折衷:FiLM中用于预测尺度的缩放平移系数的数目与网络参数数目成线性关系,且在实际中,FiLM有足够的能力在各种场景下对复杂现象进行建模。
FiLM的缺点:
- enforce a limited inductive bias::
对于有些问题,借助较强的inductive bias可能会更容易解决。因此加入一些task-relavant的inductive bais 一般会获得性能的提升。
inductive bias的解释
- remain domain-agnostic
- Limited Data Efficiency
达到相同的性能,需要更多的数据,因此在大数据集上的效果会更好
这些缺点也使得FiLM对于特异性任务的泛化性更强,可以广泛应用在各种任务中。 - 需要仔细的正则化
FiLM非常容易过拟合,需要非常细心的进行正则化,尤其是对于FiLM generator网络(如L2 weight decay, 使用线性层而不是RNN来构建generator网络)有关详细的讨论见链接
Feature-Wise 的解释
By feature-wise, we mean that scaling and shifting are applied element-wise, or in the case of convolutional networks, feature map -wise.
假设Z为条件信息,X为条件层的输入:
FiLM
(
x
)
=
γ
(
z
)
⊙
x
+
β
(
z
)
\operatorname{FiLM}(\mathbf{x})=\gamma(\mathbf{z}) \odot \mathbf{x}+\beta(\mathbf{z})
FiLM(x)=γ(z)⊙x+β(z)
即对每一个输入都逐个进行仿射变换,下图说明了对一维向量和多个二维特征图进行处理的过程:
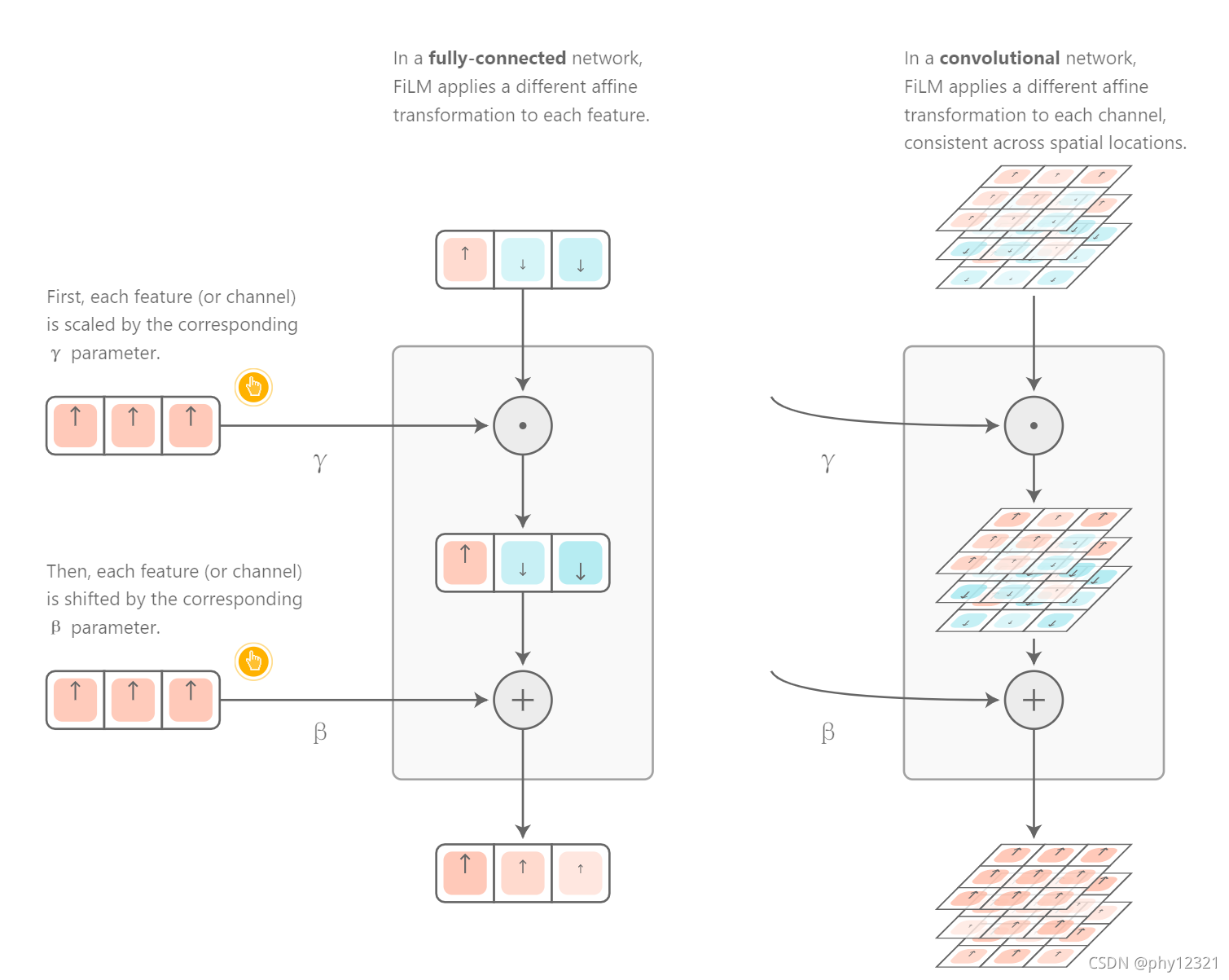
FiLM的容量解释
FiLM只是一个简单的仿射变换,但是有相当大的容量,可以广泛应用在NLP、CV任务中。实际上,其大容量是借助FiLM层后面的深度神经网络实现的。后续的神经网络层可以将简单的线性变化转化为复杂的非线性变化。例如,作者的 消失实验表明,在CNN早期使用一层FiLM可以获得与在整个网络中使用4层FiLM大致相同的性能。如果FiLM层后面没有任何神经网络层,FiLM的容量将非常有限,正好是简单仿射变换的容量。
使用FiLM的一些建议
- 首先注意观察过拟合的发生。如果模型过拟合,调整正则化超参数并尝试使用更简单的网络架构,特别是对于预测FiLM增益和偏差的网络(FiLM generator)。
- 如果需要更好的性能或数据效率,可以通过添加与任务相关的归纳偏差来提升FiLM。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)