论文 代码 官方原理与实现详解
发展YOLO系列并方便支持实例分割和斜框检测等任务,亮点:
- 设计兼容性backbone和neck,采用大核深度可分离卷积;
- 动态标签分配中采用软标签计算匹配损失;
- 结合训练达到实时检测、实时实例分割和斜框检测SOTA。
2. 相关工作
高效的目标检测神经架构。为了提高模型效率,采用人工设计或神经架构搜索的方式主要研究高效骨干网络、模型放缩策略和多尺度特征增强三方面。最近的工作也探索了使用模型重新参数化来提高推理速度。本研究进行了骨干与neck兼容的整体架构设计,采用基于大核深度卷积构建的模块提升检测器效率。
目标检测标签分配。之前的方法在标签分配中主要采用IoU作为匹配标准来比较真值框与模型预测框或锚框。后续的工作进一步研究了更多的匹配标准,例如目标中心。辅助检测头也被研究来加速和稳定训练。受端到端目标检测匈牙利分配的启发,动态标签分配的研究显著提升了收敛速度和模型精度。不同于这些策略中使用的匹配代价函数与损失一样,本研究提出使用软标签来计算匹配代价函数,增大高质量和低质量匹配之间的差异,从而使训练更稳定并加速收敛。
实例分割。之前的方法研究了多种范式,包括mask classification、Top-Down、Bottom-Up等。最近一些工作尝试有或无边界框的一阶段实例分割。这些方法的一种代表是基于动态核,学习获取学习参数和密集特征图的动态核,并用来与掩膜特征图进行卷积。受此启发,本文通过kernel prediction和mask feature heads扩展RTMDet来进行实例分割。
旋转目标检测。斜框目标检测除了预测目标的位置和类别之外,还预测方向。基于通用目标检测器(RetinaNet或Faster R-CNN)发展起不同的特征提取网络解决旋转产生的特征不匹配问题。也有多种旋转框表达的研究(高斯分布、凸集)来简化旋转边界框回归任务。不同于这些方法,本文对通用目标检测器做了最小化的改动 (添加角度预测分支,替换GIoU为Rotated IoU损失),揭示了通过模型结构和通用检测数据集预训练可以使高精度通用目标检测器变成高精度旋转目标检测器。
3. 方法
RTMDet是典型的一阶段目标检测器。文章对模型高效的改进是通过采用大核卷积构建基础模块,以及平衡模型深度、宽度和分辨率。进一步探究了使用软标签的动态标签分配策略、更好的数据增强和优化策略组合来提升模型精度。RTMDet框架扩展性良好,可以通过很少的修改支持实例分割和旋转框检测。
3.1 主要架构
架构是一阶段检测器,包括backbone、neck和head。最近的YOLO系列大都采用CSPDarkNet作为backbone架构,包含4个阶段,每个阶段包含多个基础模块。neck利用backbone的多尺度特征,并采用和backbone相同的基础块进行bottom-up和top-down的特征传播来增强金字塔特征图。最后,检测头基于不同尺度的特征图预测目标框和类别。通过核和掩膜特征获取头,模型可以扩展支持实例分割。
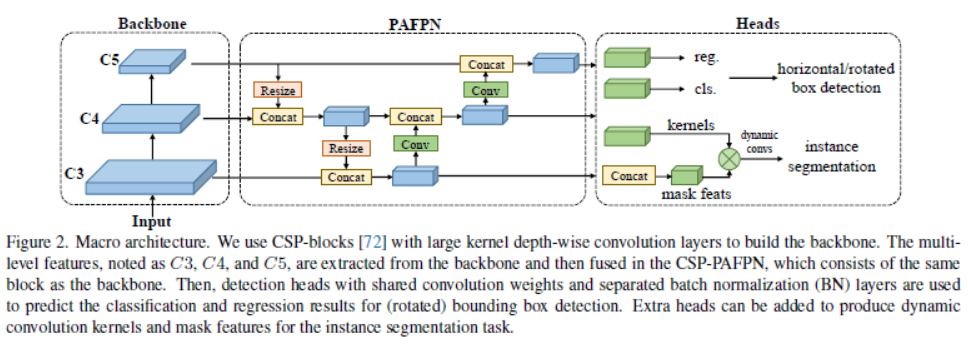
3.2 模型架构
基础模块。骨干网络中大而有效的感受野对密集预测任务(检测、分割)非常有益,因为其能更加全面的捕获和建模图像语义。然而,之前的工作(例如空洞卷积和non-local模块)计算昂贵,限制了其在实时目标检测中的应用。最近的研究重新讨论了大核卷积,发现可以通过depth-wise卷积在合理计算代价下增大感受野。受此启发,本研究在CSPDarkNet中引入5*5 depth-wise卷积(Fig.3b)来增加有效感受野。其能进行更全面的语境建模并显著提升精度。

值得注意的是,最近的一些实时目标检测器研究了重新参数化的3*3卷积(Fig.3c&d)。尽管其能在推理时有效提升精度,但也有副作用,例如降低了训练速度增加了训练存储。其同样增加了模型量化到低bit时的误差,需要通过重新参数化优化器和量化感知训练进行补偿。相比之下,大核卷积是更加简单有效的选择。
模型宽度与深度的平衡。由于在大核卷积后增加了1*1点卷积(Fig.3b),基础模块的层数也随之增加。这阻碍了每层的并行计算导致降低了推理速度。为了解决这个问题,本研究减少了每个骨干网络阶段的模块数并适度的增加模块的宽度来提升并行化与模型能力,最终在不牺牲精度的情况下提升了推理速度。
backbone与neck的平衡。为了增强多尺度特征,之前的工作要么使用更大的backbone要么使用更重(更多的特征金字塔连接和融合)的neck。然而,其同样增加了计算量和内存。因此,本研究采用另一种策略,通过增加neck中基础模块的膨胀率使其具有相似的能力,实现了更好的计算-精度平衡,将更多的参数和计算从backbone放到neck。
共享检测头。实时目标检测器大都采用不同特征尺度分离的检测头来增强模型性能,而不是跨尺度的共享检测头。本研究比较了不同的方案并选择跨尺度共享参数但采用不同BN层的检测头来减少检测头的参数量同时保持精度。同时,BN相比其它的归一化方法(例如Group Normalization)更加高效,因为在推理时直接使用训练中的统计。
3.3 训练策略
标签分配和损失。为了训练一阶段检测器,需要通过不同的标签分配策略将每个尺度的密集预测与真值框进行匹配。最近的工作采用动态标签分配策略,其采用与训练损失一致的代价函数作为匹配标准。然而,我们发现这种代价计算存在局限。因此,我们提出了一种基于SimOTA的动态软标签分配策略,其代价函数表达为:

其中Ccls、Ccenter、Creg分别为分类代价、区域先验代价和回归代价。三个参数 权重分别为1,3,1。
之前的方法通常采用二值标签来计算分类代价,会使具有高分类得分但错误边界框的预测得到低的分类代价,反之亦然。为了解决这个问题,在Ccls中引入软标签:

这个修改是受GFL(Generalized Focal Loss) 启发,其采用预测框与真值框的IoU作为软标签来训练分类分支。这种分配中的软分类代价不仅重新给了不同回归质量不同的匹配代价,也避免了由于二值标签导致的噪声或不稳定匹配。
采用Generalized IoI作为回归代价时,最大最小匹配的差异小于1。这使得难于区分高质量与低质量匹配。为了使不同真值-预测对的匹配质量更加差异化,研究采用IoU的对数作为回归代价,而不是损失函数中采用的GIoU,其放大了低IoU值匹配的代价。回归代价Creg表达为:

区域代价Ccenter采用软中心区域代价替代固定中心先验来使动态代价匹配更稳定

超参数alpha, beta设置为10和3。
缓存Mosaic和Mixup。诸如Mixup和CutMix这种跨样本增强在新近的目标检测器中广泛应用。这些增强很有效,但同时也带来了两个副作用。一是在每次迭代时都需要加载多幅图像来生成训练图像,引入了更多的数据加载代价减缓了训练。二是生产的训练样本是噪音,可能不属于数据集的真实分布,影响模型学习。
本研究利用缓存机制提升MixUp和Mosaic减少其对数据加载的消耗。通过使用缓存机制,混合图像的耗时可以接近单图处理水平。缓存操作通过缓存长度和popping方法控制。大的缓存长度和随机popping方法基本等效于原始的非缓存操作。同时,小缓存长度和First-In-First-Out(FIFO)popping可以被认为近似于重复增强,即在相同或连续的batch中使用不同的数据增强操作混合相同的图像。
两阶段训练。为了减少强数据增强产生的“噪声”样本的副作用,YOLOX采用了一种两阶段训练策略,第一阶段使用强数据增强,包括Mosaic、MixUp和随机旋转裁切,第二阶段使用弱数据增强,例如随机重采样和翻转。由于初始化训练阶段的随机旋转剪切等强增强导致输入和变换后的标注不匹配,YOLOX在第二阶段调优回归分支添加了L1损失。为了解耦数据增强和损失函数,研究在第一阶段280轮的训练排除了这些数据增强,通过增加每个训练样本的混合图像数量到8来补偿增强的强度。在最后的20轮,换做Large Scale Jittering(LSJ),使得模型能在更加接近真实数据分布域上进行微调。为了进一步使训练更加稳定,研究采用AdamW作为优化器,其很少用在卷积目标检测器中,但默认用于视觉transformer。
3.4 扩展到其他任务
实例分割。研究使用简单修改扩展RTMDet支持实例分割,称为RTMDet-Ins。如图4所示,基于RTMDet增加额外分支,包括核预测头和掩膜特征头,类似于CondInst。掩膜特征头包括4个卷积层,从多层特征中提取8通道掩膜特征。核预测头对每个实例预测一个169维矢量,其分解成3个动态卷积核通过与掩膜特征和坐标特征交互来生成实例分割掩膜。为了进一步利用掩膜标注里的先验信息,研究利用掩膜质心代替框中心计算动态标签分配中的软区域先验。研究采用dice损失作为实例掩膜的监督。
旋转目标检测。根据旋转目标检测回头通用(正框)目标检测的相似性,仅需3步能将RTMDet扩展到旋转目标检测器,即RTMDet-R。(1)添加1*1卷积作为旋转角度的预测分支;(2)更新正框代码支持旋转框;(3)替换GIoU为损失为旋转IoU损失。模型结构高度优化的RTMDet保证了RTMDet-R在旋转目标检测任务的高性能。同时,RTMDet-R与RTMDet共享了尽量多的参数,也保证了RTMDet在通用检测数据集(COCO)的预训练可以作为旋转目标检测的良好初始化。
4. 实验
4.1 实现细节
目标检测和实例分割。COCO数据集,检测与实例分割分别使用box AP和mask AP。score 0.001,保留top 300框进行验证。但为了加速效率,在消融实验中使用score 0.05,top 100。降低0.3%AP。
旋转目标检测。DOTA数据集。单尺度训练测试,1024尺寸256重叠。多尺度,重采样到0.5、1.0、1.5,裁剪到1024,重叠500。
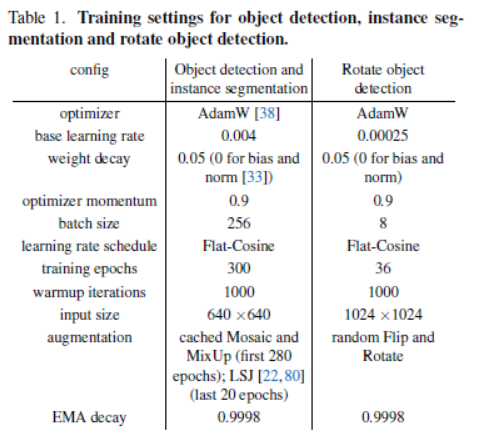
模型耗时测试采用半精度FP16,基于NVIDIA 3090 GPU with TensorRT 8.4.3 and cuDNN 8.2.0。不统计NMS时间。
4.2 基准结果
目标检测。COCO数据集上,同YOLOv5、YOLOX、YOLOv6、YOLOv7和YOLOLOE比较,在参数-精度平衡上SOTA。
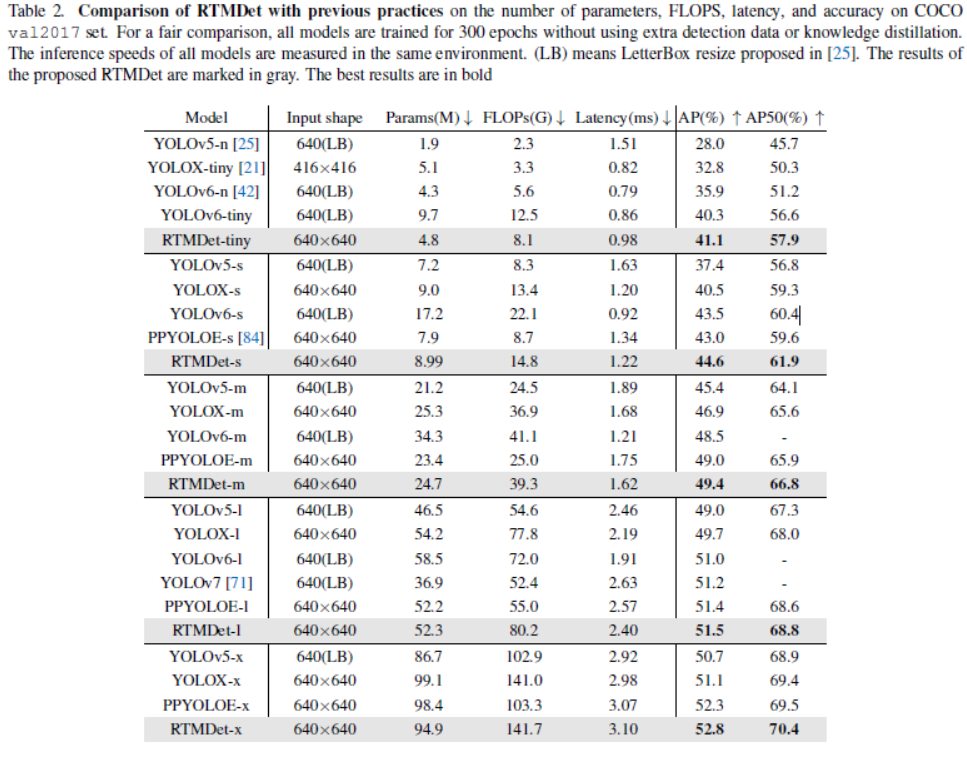
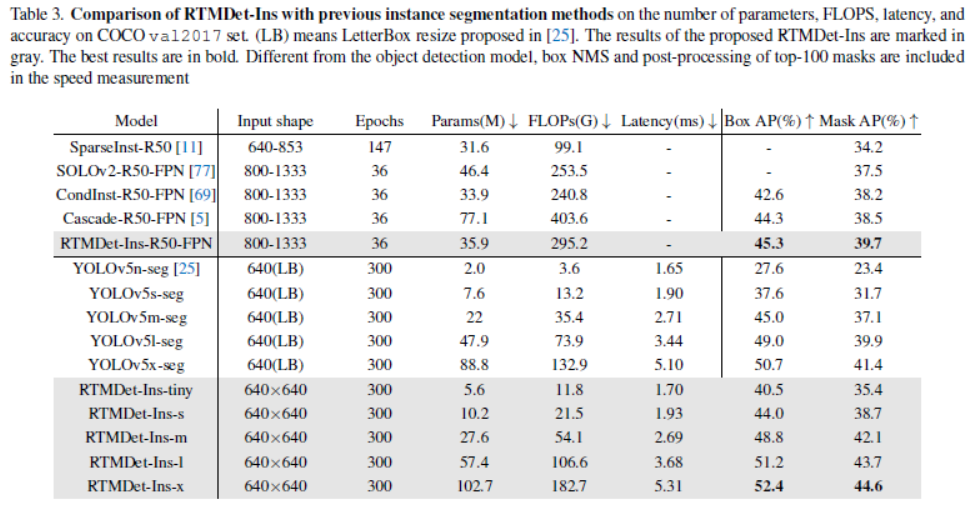
实例分割。保持实时性的同时,比之前的SOTA提升大于3%AP。
旋转目标检测,精度达到二阶段水平,在COCO预训练支持下,甚至SOTA。RTMDet-R避免采用特殊运算,使得其能更好地用于不同硬件。

4.3 模型结构消融实验
大核。试验3、5、7,5*5比较平衡。
多特征尺度平衡。depth-wise卷积增加深度减少推理速度,因此减少第2、3阶段的模块数。9减到6,速度提升20%,但AP下降0.5%,通过在每个阶段最后增加通道注意力(CA),在AP损失0.1%的情况下,速度提升7%。
backbone和neck平衡。试验发现使neck和backbone有相似能力能实现相似精度下更快速度,对大小实时检测器均有效。
检测头。比较多尺度特征不同的共享策略。发现不同特征共享权重检测头的BN会导致精度下降,这是由于不同特征尺度统计的差异。使用不同的特征头可以解决这个问题,但提升了参数量。而对不同特征尺度使用相同权重但不同BN统计能获得最佳的参数-精度平衡。

4.4 训练策略消融实验
标签分配。baseline采用SimOTA,Focal Loss和GIoU。Fig.6b标签分配策略对比。Fig6c采用更长更强数据增强的训练,比SimOTA提升1.3%AP。

数据增强。Mosaic and MixUp缓冲分别加速约3.6倍和1.5倍。第二阶段使用LSJ代替Mosaic and MixUp会给RTMDet-s和l分别带来2%和1.5%的提升。表明Mosaic and MixUp是更强的数据增强会带来更多噪音。当缓冲约为10张图像并采用FIFO弹出方法时,可能同一batch里使用不同的增强混合相同的图像,类似于重复增强,对tiny和small模型有轻微提升。相较于YOLOX,本研究在第一阶段弃用随机旋转裁切,因为其导致框标注和输入的错位。取而代之的是,研究增加混合图像的数量从5到8来保持数据增强的强度。

优化策略。SGD在强增强时收敛不稳定,研究采用AdamW带0.05weight decay。为了避免余弦学习率早中期学习率下降过快产生过拟合,采用flat-cosine,即前半段采用固定学习率,后半段采用余弦学习率。这个修改提升了0.3%AP。weight decay带来0.9%AP提升。最终使用通过RSB(Resnet strikes back: An improved training procedure in timm)训练策略得到的ImageNet预训练骨干带来了0.3%AP的提升。

4.5 Step-by-step结果
以YOLOX为baseline,逐步添加改进试验。 保持效率,同时提升了4.3%的AP。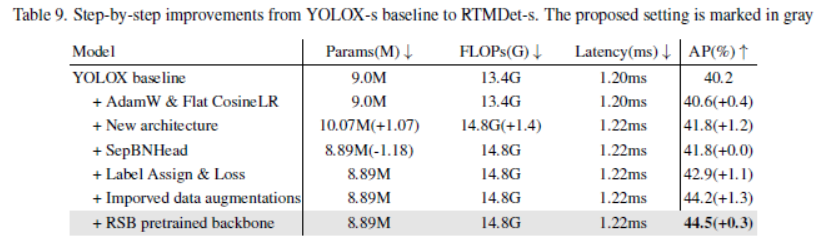
5. 结论
论文实证和综合性研究了实时检测器的每个关键组件,包括模型结构、标签分配、数据增强和优化。进一步研究了扩展到实例分割和旋转目标检测的最小改进。RTMDet展示出了在工业级应用中精度-速度的优越平衡。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)