VINS技术路线
写在前面:本文整和自己的思路,希望对学习VINS或者VIO的同学有所帮助,如果你觉得文章写的对你的理解有一点帮助,可以推荐给周围的小伙伴们,当然,如果你有任何问题想要交流,欢迎随时探讨。话不多说,下面上正文。
VINS代码地址:https://github.com/HKUST-Aerial-Robotics/VINS-Mono https://github.com/HKUST-Aerial-Robotics/VINS-Mono
https://github.com/HKUST-Aerial-Robotics/VINS-Mono
参考文档:1.VINS-Mono A Robust and Versatile Monocular Visual-Inertial State Estimator
2.Quaternion kinematics for the error-state Kalman filter
新加内容:
状态估计与卡尔曼滤波理解分析
如果想单独了解某一块内容,可以看分开讨论的部分,内容相同:
VINS理论与代码详解0——理论基础白话篇
VINS理论与代码详解1——框架解析
VINS理论与代码详解2——单目视觉跟踪
VINS理论与代码详解3——IMU预积分(最近更新IMU残差雅各比计算推导)
VINS理论与代码详解4——初始化
VINS理论与代码详解5——基于滑动窗口的单目视觉紧耦合后端优化模型(最近更新视觉雅各比计算推导)
最近整理了ORB_SLAM2视觉惯性紧耦合的理论分析,想了解的可以点开下面的连接:
ORB_SLAM2视觉惯性紧耦合定位算法详解
如果只想单独了解ORB_SLAM2视觉惯性紧耦合的理论分析某一块的话,可以看分开讨论的部分,内容都是相同的:
ORB_SLAM2视觉惯性紧耦合定位技术路线与代码详解0——整体框架与理论基础知识
ORB_SLAM2视觉惯性紧耦合定位技术路线与代码详解1——IMU流型预积分
ORB_SLAM2视觉惯性紧耦合定位技术路线与代码详解2——IMU初始化
ORB_SLAM2视觉惯性紧耦合定位技术路线与代码详解3——紧耦合优化模型
在这些博客中经常提到的一些关键数学知识总结到下面,随时更新欢迎阅读指正:
视觉SLAM常见的QR分解SVD分解等矩阵分解方式求解满秩和亏秩最小二乘问题(最全的方法分析总结)
凸函数的Hessian矩阵与高斯牛顿下降法增量矩阵半正定性的理解
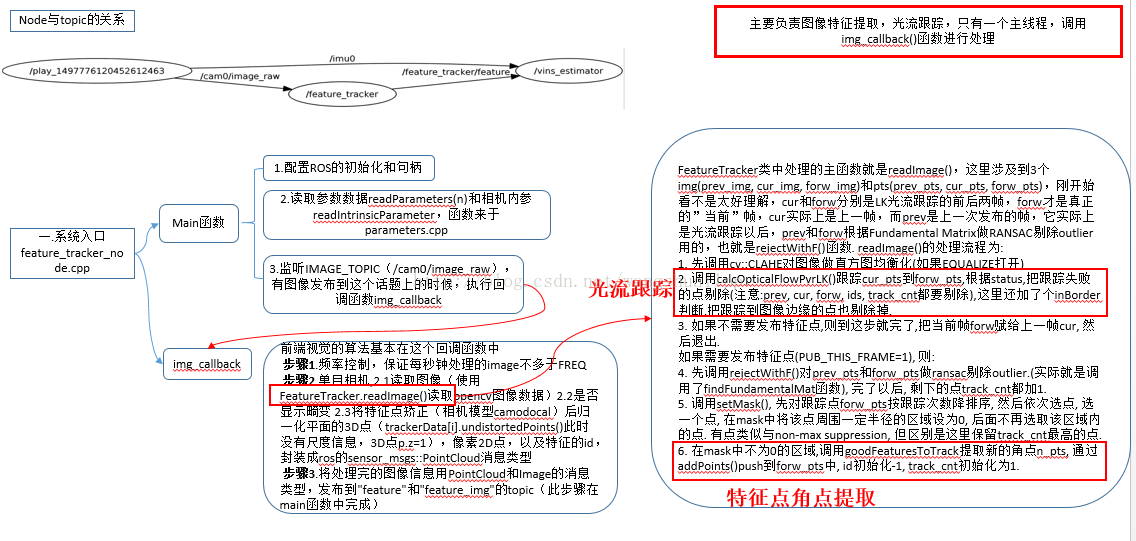
VINS代码主要包含在两个文件中,分别是feature_tracker和vins_estimate,feature_tracker就像文件的名字一样,总体的作用是接收图像,使用KLT光流算法踪;vins_estimate包含相机和IMU数据的前端预处理(也就是预积分过程)、单目惯性联合初始化(在线的标定过程)、基于滑动窗口的BA联合优化、全局的图优化和回环检测等。要想真正的理解一个SLAM框架,必须真正搞懂其对应的算法模型,然后才能研究其代码逻辑,最后做到相得益彰的效果,因此本次讲解主要是结合论文中的理论知识这和两个文件中的代码进行详细的探讨。整体的框架都比较熟悉,如下图所示,第一部分是Measuremen Preprocessing:观测值数据预处理,包含图像数据跟踪IMU数据预积分;第二部分是Initialization:初始化,包含单纯的视觉初始化和视觉惯性联合初始化;第三部分Local Visual-Inertia BA and Relocalization:局部BA联合优化和重定位,包含一个基于滑动窗口的BA优化模型;第四部分Global Pose Graph Optimization:全局图优化,只对全局的位姿进行优化;第五部分Loop detection:回环检测。

一.Feature_tracker文件夹中
首先讲第一部分,也就是纯粹的图像处理部分内容,在论文中的第IV点观测值预处理的A部分视觉前端处理,为了更好的理解代码,有必要将论文中的相关内容和大家讨论一番。
论文内容:每当进入新的图像,都会使用KLT稀疏光流法进行跟踪,同时提取100-300个角点信息,我的理解是角点是用来建立图像,光流跟踪是用来快速定位。同时在这里还进行了关键帧的选取,主要是两个剔除关键帧的策略,分别是平均视差法和跟踪质量法。平均视差法:如果当前帧的和上一个关键帧跟踪点的平均视差超出了一个设定的阈值,就将当前帧设为关键帧。这里有一个问题,就是旋转和平移都会产生视差(不只是平移哦),当出现纯旋转的时候特征点无法被三角化,无法计算出旋转值,也就无法计算跟踪点间的平均视差,为了解决这一问题,采用短时的陀螺仪观测值来补偿旋转,从而计算出视差,这一过程只应用到平均视差的计算,不会影响真实的旋转结果。
具体代码实现:主要负责图像角点提取和光流跟踪,只有一个主线程。主要是三个源程序,分别是feature_tracker、feature_tracker_node以及parameters。feature_tracker_node是特征跟踪线程的系统入口,feature_tracker是特征跟踪算法的具体实现,parameters是设备等参数的读取和存放。
1. feature_tracker_node.cpp系统入口
(1) main()函数
步骤1:readParameters(n);读取参数,是config->euroc->euroc_config.yaml中的一些配置参数。
步骤2: trackerData[i].readIntrinsicParameter(CAM_NAMES[i]);在这里NUM_OF_CAM设置成常量1,只有一个摄像头(单目),读取相机内参。
步骤3:判断是否加入鱼眼mask来去除边缘噪声
步骤4: ros::Subscriber sub_img = n.subscribe(IMAGE_TOPIC, 100,img_callback); 订阅话题和发布话题,监听IMAGE_TOPIC(/cam0/image_raw),有图像发布到这个话题上的时候,执行回调函数,这里直接进入到img_callback函数中接收图像,前端视觉的算法基本在这个回调函数中。
1) img_callback(const sensor_msgs::ImageConstPtr &img_msg)接收图像
步骤1: 频率控制,保证每秒钟处理的image不多于FREQ,这里将平率控制在10hz以内。
步骤2: 处理单目相机
步骤2.1: trackerData[i].readImage(ptr->image.rowRange(ROW * i, ROW *(i + 1)));读取到的图像数据存储到trackerData中,读取完之后如果图像太亮或太黑(EQUALIZE=1),使用createCLAHE对图像进行自适应直方图均衡化,如果图像正常,设置成当前图像。在读取图像的时候进行光流跟踪和特征点的提取。FeatureTracker类中处理的主要函数就是readImage(),这里涉及到3个img(prev_img, cur_img, forw_img)和pts(prev_pts,cur_pts, forw_pts),两者是相似的。刚开始看不是太好理解,cur和forw分别是LK光流跟踪的前后两帧,forw才是真正的“当前”帧,cur实际上是上一帧,而prev是上一次发布的帧,它实际上是光流跟踪以后,prev和forw根据Fundamental Matrix做RANSAC剔除outlier用的,也就是rejectWithF()函数. readImage()的处理流程为:
①先调用cv::CLAHE对图像做直方图均衡化(如果EQUALIZE=1,表示太亮或则太暗)
PS:CLAHE是一种直方图均衡算法,能有效的增强或改善图像(局部)对比度,从而获取更多图像相关边缘信息有利于分割,比如在书架识别系统的书脊切割中,使用CLAHE可以比传统的直方图增强方法达到更好的增强书脊边界直线的效果,从而有利于后续的书脊边界直线的检测和提取。还能够有效改善AHE中放大噪声的问题,虽然在实际中应用不多,但是效果确实不错。
②调用calcOpticalFlowPyrLK()跟踪cur_pts到forw_pts,根据status,把跟踪失败的点剔除(注意:prev, cur,forw, ids, track_cnt都要剔除),这里还加了个inBorder判断,把跟踪到图像边缘的点也剔除掉.
③如果不需要发布特征点,则到这步就完了,把当前帧forw赋给上一帧cur, 然后退出.如果需要发布特征点(PUB_THIS_FRAME=1), 则执行下面的步骤
④先调用rejectWithF()对prev_pts和forw_pts做ransac剔除outlier.(实际就是调用了findFundamentalMat函数), 在光流追踪成功就记被追踪+1,数值代表被追踪的次数,数值越大,说明被追踪的就越久
⑤调用setMask(), 先对跟踪点forw_pts按跟踪次数降排序, 然后依次选点, 选一个点, 在mask中将该点周围一定半径的区域设为0, 后面不再选取该区域内的点. 有点类似与non-max suppression, 但区别是这里保留track_cnt最高的点.
⑥在mask中不为0的区域,调用goodFeaturesToTrack提取新的角点n_pts, 通过addPoints()函数push到forw_pts中, id初始化-1,track_cnt初始化为1.
整体来说需要注意的是:光流跟踪在②中完成,角点提取在⑥中完成
步骤2.2:判断是否需要显示畸变。
步骤2.3:将特征点矫正(相机模型camodocal)后归一化平面的3D点(此时没有尺度信息,3D点p.z=1),像素2D点,以及特征的id,封装成ros的sensor_msgs::PointCloud消息类型的feature_points实例中;将图像封装到cv_bridge::CvImageConstPtr类型的ptr实例中
步骤3: 发布消息的数据
pub_img.publish(feature_points);
pub_match.publish(ptr->toImageMsg())
将处理完的图像信息用PointCloud实例feature_points和Image的实例ptr消息类型,发布到"feature"和"feature_img"的topic(此步骤在main函数中完成)
至此,已经将图像数据包装成特征点数据和图像数据发布出来了,下面就是在开一个线程,发布一个话题,接收这两种消息,也就是下面的vins_esitimate文件中做的事。
下面是具体的流程图:
二.Vins_estimate文件夹中
下面到第二部分了,也是整个框架的重点和难点,估计要花很长的时间学习和总计理论知识和代码逻辑,这一部分还是从论文的理论知识讲起,然后再附上代码消化理解。
论文内容:
1. 论文第IV点的B部分IMU预积分,
IMU预积分的作用是计算出IMU数据的观测值(就是IMU预积分值)以及残差的协方差矩阵和雅各比矩阵,那就要清楚的明白为什么要计算这三个量?计算出这三个量为什么就可以和视觉观测值进行耦合?如果你现在回答不出来,请好好想一想自己以前学到的知识,关于视觉的这三个量,视觉中观测值是用来计算残差的(也就是误差),残差的雅各比矩阵是优化中下降的方向(也就是梯度),很少提及的协方差矩阵(但很重要)其实是观测值对应的权值(因为有很多观测值),现在是不是很清楚明白了?具体使用来说,这三个量为后面的联合初始化提供初值以及后端优化提供IMU的约束关系。原始陀螺仪和加速度计的观测值数据:

第一个式子等式左边是加速度测量值(你可以从加速度计中读到的值,带尖括号的是带误差的数据),等式右边是加速度真实值(其实就是准确的值,我们需要得到的是这个真实值)加上加速度计的偏置、重力加速度(注意是世界坐标系下)和加速度噪声项。第二个式子等式左边是陀螺仪测量值,等式右边是陀螺仪真实值加上陀螺仪偏置和陀螺仪噪声项。这里的值都是IMU(body)帧坐标系下的。这里假设噪声是服从高斯正态分布,而偏置服从随机游走模型。
有上面最原始的式子积分就可以计算出下一时刻的p、v和q:

状态量上标代表的是所处的坐标系,下标是具体哪一帧数据。这里等式左边的值都是世界坐标系下(W)bk+1帧的值。有必要解释下公式的推导,P和V的公式比较简单,q的公式需要解释下,一般情况下q_w_bk+1=q_w_bk*q_bk_bk+1,注意这里的乘法是四元数的乘法,和一般的旋转矩阵直接相乘方式不同,而q_bk_bk+1就是后面的积分公式,积分可以理解成q_bk_t*q_t_t1*q_t1_t2...,单独看q_bk_t*q_t_t1,将四元数的乘法转换成一般的乘法,论文这里使用四元数的右乘法则,将q_bk_t*q_t_t1转换成了1/2*Ω(w)*dt*q_bk_t。q推倒公式如下,公式中的()R是汉密尔顿右乘

从整个式子可以看出来这里的状态传播需要bk帧下的旋转,平移和速度,当这些开始的状态发生改变的时候,就需要重新传播IMU观测值,也就是说状态传播方程要重新计算和修改(而在slam的优化过程中,bk帧下的旋转,平移和速度是实时优化更新的状态量)。我们想要一次性就求出bk和bk+1之间的状态传播,因此选用预积分模型(最初提出预积分的外国大佬是将世界坐标系转换到求状态的变化量,其实两者的原理都一样,预积分求的值都是变化量),两边同时乘以世界到bk帧坐标系的转换,如下图所示,然后提出等式右边只与加速度和角速度有关的量进行积分,如公式6:
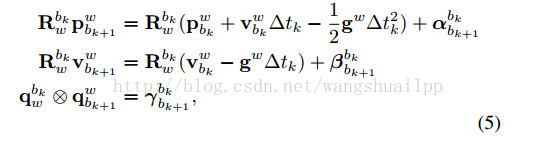

IMU预计分真实的意义在于其结果是一段短时间内(tk~tk+1)IMU真实旋转,位移和速度的变化量,而IMU短时间的变化量是非常准确的。到这里其实只要求出公式6中的积分值,真的预积分的值就得到了,这里bk是参考帧,从式6中可以看出,在bk到bk+1帧间,这里要求的三个预计分状态量只与IMU的偏置状态量有关系,而与其他状态无关,(状态量就是我们一直在优化的量,会一直变化),由于IMU的bias会一直修改,那么上面的预积分也会不断的重新积分(这很麻烦,也很耗时),所以我们希望bias变化的时候,我们可以很简单的就重新计算得到真实的预积分,而不需要再麻烦的重复积分计算预积分。我们的做法是,首先根据当前已知的bias通过公式(6)计算当前的预积分,当这里的偏置变化特别小的时候,我们可以使用一阶线性展开来调整预积分,这里提一下雅可比矩阵就是一阶偏导(我想大家应该都是知道的),如下公式12 所示:

所以要想求出这个临时的状态量,就必须求出等式右边的两部分值,第一个部分还是原来的积分形式(就像公式6那样),是预积分的主体,论文中使用的是最简单的欧拉积分法进行展开(取第i时刻值的斜率乘以时间差加上i时刻的初值,就得到i+1时刻的值),但是在代码中作者也提出了采用的是中值积分(顾名思义这里的斜率取得是i和i+1中点(2i+1)/2的时刻斜率).公式7是采用欧拉积分的结果。这里前面有一定的说明,一开始abkbk,bbkbk等是零,旋转是单位旋转,注意整个过程把噪声设为0。

第二部分其实就是对应的一阶偏导(对加速度计偏置和陀螺仪偏置的),一阶偏导的求法在下面进行介绍,到这里我们已经求出了临时状态量的测量值,也就可以求出状态量测量值。
论文到这一步预积分其实已经做了一半了,也就是完成了测量值的求解,还差什么呢?当然是协方差矩阵了,下面重点求解协方差矩阵,顺便把上面没有求出的陀螺仪和加速度计偏置的雅各比矩阵求出来。
如何求协方差矩阵呢?怎么从数学的定义里去求呢?这里要用到SLAM中的神作state estimation for robotic,建立一个线性高斯误差状态传播方程,由线性高斯系统的协方差,就可以推导出方程协方差矩阵了,也就是测量状态的协方差矩阵了。也就是说还是需要前面求解状态测量值的公式6。注意代码中真正求解公式6使用的是中值法,所以为了和代码中相一致,下面的求解过程我也才用中值法的方式,为求解需求我们先补充点干货:
首先需要将上面的四自由度的旋转转换成三个维度的状态量,这是由于四自由度的旋转存在过参数数化的情况,过参数化求解会需要引入额外的约束(单位四元数性质),因此将误差看成是一个扰动定义式8:
然后有下面的两张图定义出来离散状态下的预积分过程:

然后有下面的两张图定义出来离散状态下的预积分过程:


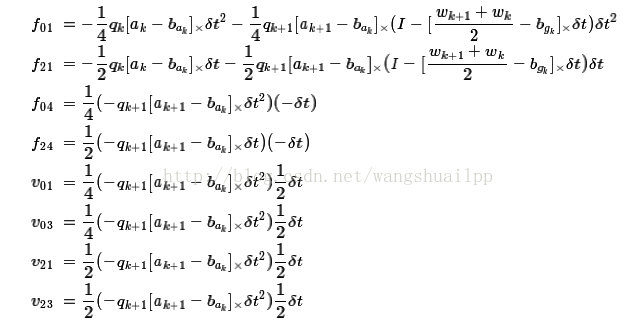
最后得到图中的线性误差状态传播模型,由此得到IMU预积分测量值的协方差矩阵和雅各比矩阵,预积分的雅各比矩阵直接代入到公式12中计算出更加精确的传播状态值,而IMU误差运动方程的协方差矩阵自然是在后面优化中使用,后面优化使用的有IMU误差的运动方程,即 。这里
。这里 是预积分的值,
是预积分的值, 是估计出来的积分值。上面求出的
是估计出来的积分值。上面求出的 可以表示成
可以表示成 ,我们希望一步步的迭代计算出来
,我们希望一步步的迭代计算出来 的协方差矩阵和jacobian矩阵,根据该公式预测k+1时刻的IMU误差方程的预积分和jacobian(这部分可以参考视觉slam十四讲的10.1.2的IMU运动方程的预测先验),如上面图片的公式。
的协方差矩阵和jacobian矩阵,根据该公式预测k+1时刻的IMU误差方程的预积分和jacobian(这部分可以参考视觉slam十四讲的10.1.2的IMU运动方程的预测先验),如上面图片的公式。
需要格外注意上面求出的雅各比矩阵是预积分值的雅各比,我们还需要求一个IMU残差的雅各比矩阵,WHAT?还有两个雅各比矩阵,惊不惊喜意不意外?但情况确实如此,所以还不赶快从床上爬起来继续撸一把公式。上面求得的雅各比矩阵是用来计算预积分值时用到的,下面要求的IMU残差的雅各比矩阵是在紧耦合的时候做下降梯度,在最前面已经提到过。在求残差的雅各比之前,再提一下残差是如何计算的吧,预积分相当于测量值(就是真值,因为没有比这个更准确的值了,那当然就是真值了),要估计的状态就是估计值,所以预积分测量值减去状态估计值就是残差,在后面会提到需要估计的IMU估计值有p,v,q,ba,bg。P和q的估计值初始值比较好得到(和视觉相关,可以直接用视觉的初值),而v,ba,bg这三个量的估计值初始值就比较难得到了,因为视觉没有这三个初始量,就会用到下面的联合初始化得到初始的这三个量。下面直接上残差公式和要优化的状态量:
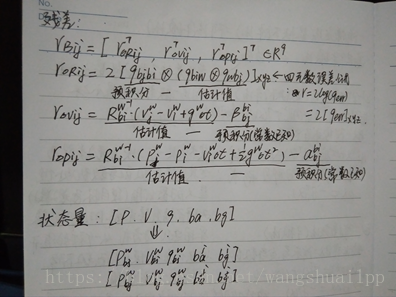
需要求解的残差雅各比矩阵是残差对估计状态量的一阶偏导,残差向量有三个,状态向量有2*5=10个。所以需要计算残差向量对状态向量的一阶偏导。首先需要提出的是对于偏置求偏导是比较复杂的,所以对于预积分的计算采取的是一阶泰勒展开,这样就相对简单了。也就是论文中的公式(12)。
需要解释下为什么旋转向量的误差前面会有一个系数2,这和四元数转换成旋转向量之间存在一个2倍的关系有关

(1)旋转四元数残差的雅各比矩阵

可以看出旋转四元数残差包含的状态量只有qi,qj,big这三个变量,也就是一个三元函数求偏导过程。
(2)速度残差的雅各比矩阵
未完待续,其实可以自己推导试试。
(3)位移残差的雅各比矩阵
未完待续,其实可以自己推到试试。
到这里恭喜你已经完成了数据前端处理的所有步骤,下面直接进入初始化的过程吧!
2. 基于滑动窗口的纯视觉单目初始化
在介绍纯视觉初始化前我们首先讲一讲为什么要初始化?初始化要做什么?以及初始化的作用?我们初始化的原因是单目惯性紧耦合系统是一个非线性程度很高的系统,首先单目是无法获得空间中的绝对尺度,而IMU又必然存在偏置,在后面进行求解的时候还需要用到重力加速度(包括大小和方向),对于速度比较敏感的条件下,比如说无人机,又要精确的速度信息,因此,如何有效的在紧耦合系统处理之前计算出这些量,对整个紧耦合系统的鲁棒性有着重大的意义(其实这里就可以理解成相机标定一样,没有正确的标定好相机的内参,相机在进行定位的时候必然不准,而且很有可能会挂掉)。所以初始化要做的事其实说起来很简单,就是计算出绝对尺度s、陀螺仪偏置bg、加速度偏置ba、重力加速度G和每个IMU时刻的速度v,VINS中重点说明了加速度计偏置值一般都会和重力加速度耦合到一起(也就是被重力加速度给吸收掉),重力加速度的量级要远大于其加速度偏置,而且在初始化时间内加速度计偏置比较小,很难真正的计算得到,因此忽略加速度计偏置的影响,在初始化中不再计算。初始化的作用是不言而喻的,直接影响整个紧耦合系统的鲁棒性以及定位精度,并且初始化一般都需要一个比较漫长的时间,VINS大概需要十秒左右,ORB_SLAM2结合IMU的时间设定在15秒完成初始化。话不多说,直接进入正题。
纯视觉初始化在第V点的A部分,首先构建一个滑动窗口,包含一组数据帧。论文中提及使用的是对极几何模型的5点法求解单目相机的相对变换,包括相对旋转和无尺度信息的位移。其实基本上每个单目模型都是使用对极几何在初始化中求解两帧的相对变换,这里需要注意的是旋转是具有尺度不变性的(其实就是单位旋转,不会有尺度信息,你仔细想想是不是?),至于为什么单目没有尺度信息,我想罗嗦一句,但其实很多学习单目视觉SLAM的人都没有真正搞明白过,单目视觉没有尺度的源头是最开始两帧间的对极几何求位姿,再具体点就是求F/E或者H的时候需要将其降参一位,F从6维降到5维,H从9维降到8维,这里所降的维度就是尺度,而且必须要降。然后三角化得到相应的3d点坐标,有这些3d点和滑动窗口中其他的帧的2d点就可以进行PNP求解获得滑动窗口中的所有的位姿和特征点3d坐标,至此,纯视觉初始化就完成了。是不是很简单?当然啊,毕竟只是简单的视觉初始化,而真正复杂的是视觉惯性联合初始化,也就是我们初始化的重点和难点,所以下面的知识点一定要打起精神学啦!
3. 视觉惯性联合初始化
视觉惯性联合初始化在第V点的B部分,这里作者给定义的名字叫Visual-Inertia Alignment,即视觉惯性联合初始化(而在ORBSLAM2+IMU的论文里,作者定义的名称就叫IMU initialization,即IMU初始化),为什么定义这样一个名词,我觉得有两个意义,第一在进行陀螺仪偏置初始化的时候要同时使用到IMU测量的旋转和视觉测量的旋转,也就是要联合视觉和惯性的数据。第二这里求得的尺度S的值不仅仅是IMU的,还是视觉和IMU整个系统的尺度。在具体的讲解初始化每个过程的时候,有必要来个总体的概括,初始化在物理意义上的定义其实就是固有参数的标定,在数学模型上的定义其实就是公式(6)的矩阵方程求解,而公式(6)其实就是来自于最原始的PVQ积分公式,其中Q旋转对应着陀螺仪,而PV对应着加速度计,如果不明白的话,不要紧,看完下面的整体推导过程相信聪明的你一定会茅塞顿开。
(1) 陀螺仪偏置标定
旋转我们可以通过两种方式求得,一种是陀螺仪测量值,一种就是视觉观测值。按照正常的理解两者的大小一定是相等的(假设没有误差),但实际情况肯定有误差,我们就来看看各自的误差。陀螺仪的误差有两部分测量噪声和陀螺仪偏置,噪声暂时可以忽略(毕竟太小),而视觉的误差就只有观测噪声(也可以忽略不管),因此两者差值的绝对值就是陀螺仪偏置,将整个滑动窗口的所有的旋转做差构成了一个最小化误差模型:

公式15中第一个式子的第一项和第二项作四元数旋转的广义乘积就可以得到bk+1坐标系下相机从bk+1到bk下的相对旋转(相对bk+1),第三项是bk坐标系下陀螺仪从b到bk k+1下的相对旋转(相对bk),两者在做广义乘积,就是首先从bk到bk+1旋转,然后再从bk+1到bk旋转,相当于做差(OA+AO=0),第二个式子就是前面预积分提到的一阶线性近似。然后取最小二乘,当然也可以使用SVD分解等方法求解。注意在求得陀螺仪偏置之后要再次将陀螺仪偏置代入到预积分中再求一次预积分的值,会更加精确。
(2) 速度、重力加速度和尺度标定
作者在这里将这三个状态量统一到一个状态向量中,如公式16所示:
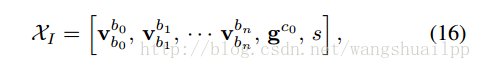
速度的是在bk坐标系下的,重力加速度在初始相机坐标系下,就像前面提到的,求解这几个量是由P、V数学模型求得,在滑动窗口中考虑到两个连续关键帧bk和bk+1,下面进行论文中公式17和19的推导:


公式推导之后就会得到论文中的公式17、18和19,我们重点关注下为什么要这样推导,以及推导得到的运动方程关系。首先为什么要进行这样的推导,这完全取决于状态向量的定义方式,我们最终要得到的方程形式左边一定是以状态向量的形式来表达的,而且还要满足其他量都是已知的(从IMU预积分和视觉跟踪得到),因此就需要将方程进行如此的变化,才能满足这样的关系。然后是最后的形式我们可以看到状态向量最终的形式维度是(n+1)*3+3+1,两个连续帧产生的运动方程的维度是3+3+3+1(vbkbk,vbk+1bk+1,gc0,s),gc0是第一个相机坐标系下的重力加速度,剩下的就是解最小二乘问题了,论文中采用的是快速的Cholesky分解。对于最小二乘求解这类方程如果有不懂的可以翻看我的另一篇博客,希望可以帮到你:
视觉SLAM常见的QR分解SVD分解等矩阵分解方式求解满秩和亏秩最小二乘问题(最全的方法分析总结) https://blog.csdn.net/wangshuailpp/article/details/80209863
https://blog.csdn.net/wangshuailpp/article/details/80209863
(3) 重力优化
上面其实已经得到了重力加速度的大小和方向,这里为什么还需要对重力进行优化呢?理由很简单,这里计算的重力吸收了重力加速度计的偏置,虽然不需要计算重力加速度计的偏置,但重力还是需要优化的,说到优化重力加速度,肯定包含两个量,大小和方向,也就是三个维度,但是一般来说大小是确定已知的(这里设为9.8),因此其实我们要做的就是优化方向,是一个两维的向量,下图是优化重力的方法以及b1,b2单位向量的方向确定模型。正切平面优化适合于对重力加速度的微调,而且只是微调方向。


4. 基于滑动窗口的单目视觉紧耦合后端优化模型
终于讲到了真正的视觉惯性紧耦合系统了,(在这里插一句,算是写博客和学习一个SLAM系统的心得吧,一开始我们可能抱着一个必胜的心态打算征服所有的知识点和难点,但到了整个过程的中期,总会出现或多或少的问题,阻碍着我们前进的步伐,你可能想放松警惕,不想太深究具体的公式和内容,急功心切的想看到终点到底是什么,但是我要提醒大家,也包括自己,最美好的以及最有价值的永远是过程,是在过程中学到的可以为一生所用的经验,只是一味着冲到终点,而忘记了过程,你最终会发现得到的只有失望。如果你不想失望的话,那就再接再厉,给自己继续加油吧!)到这里才是整个系统的重点,前面所有提及的其实都是松耦合方式,目的是给整个系统提供优化初值和状态。视觉惯性紧耦合优化模型在第VI部分,我理解的紧耦合系统是将视觉和惯性的原始观测量进行有效的组合,也就是在数据处理前就进行数据融合,VINS中是将滑动窗口内的状态量整合到一个状态向量中,如公式21所示:
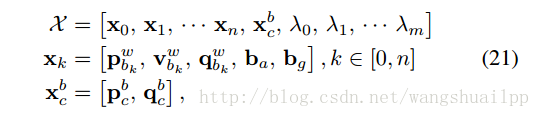
第一个式子是滑动窗口内整个状态向量,其中n是帧数,m是滑动窗口中的特征点总数,维度是15*n+6+m,第二个式子xk是在第k帧图像捕获到的IMU状态,包括位姿,速度,旋转,加速度计和陀螺仪偏置,第三个式子是相机外参,λ是特征点深度值得逆(大家一定会问,问什么这里只用特征点深度值的逆,也就是逆深度,主要是考虑稳定和满足高斯系统,不懂得可以参考高博的十四讲)。从状态向量就可以看出xk只与IMU项以及Marginalization有关,特征点的深度值只与camera和Marginalization有关,所以下面建立BA紧耦合模型的时候按照这个思路,下面建立一个视觉惯性的BA优化模型以及鲁棒核函数模型:

从公式中可以明显的看出来,BA优化模型被分成了三个部分,分别是Marginalization(边缘化)残差部分(从滑动窗口中去掉的位姿和特征点的约束),IMU残差部分(滑动窗口中相邻帧间的IMU产生)和视觉代价误差函数部分(滑动窗口中特征点在相机下的投影产生),其中鲁棒核函数针对代价函数设定(具体作用请参见视觉SLAM十四讲),鲁棒核函数的作用是去除outlier,视觉残差使用了鲁棒核函数,而imu残差没有使用,这是因为IMU数据不存在outlier。下面具体介绍着三个部分。
(1) IMU观测值残差
考虑到的是两个连续帧bk和bk+1之间的观测值,与前面的预积分模型相同,如公式24所示,还记得在IMU预积分的时候求得到协方差矩阵和观测值吗?那里求得的观测值就是测量值,协方差矩阵就是这里的协方差矩阵,而公式24前面的项就是预测的值,也称估计值,估计值和测量值之间的差值就是残差,其实这里的公式24是由公式5的右边左移得到,你发现了吗?
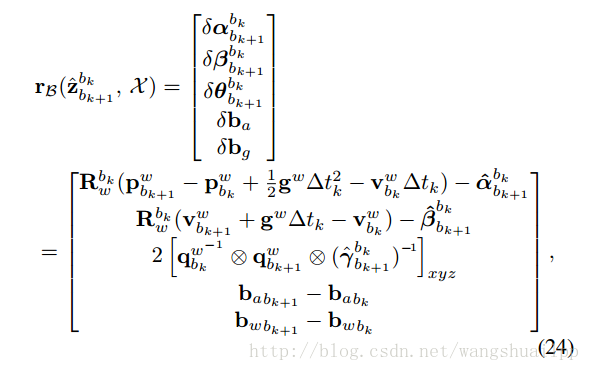
(2) 视觉观测值残差
与传统的针孔相机模型定义的重投影误差不同,论文中使用的是单位半球体的相机观测残差,是一个宽视野鱼眼或者全方位相机。相机的残差模型如下公式25所示:
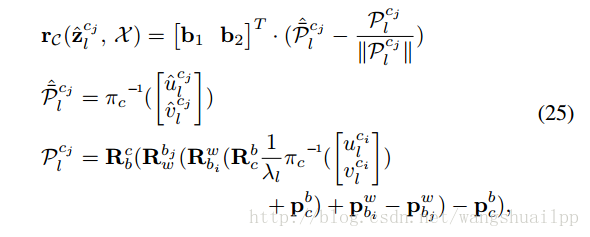
第一个式子就是残差的表达式,第二个式子是鱼眼相机反投影函数将观测到的像素坐标转换成单位向量的观测值数据,b1和b2是此单位向量的切平面上的一组基。第三个式子是重投影估计模型。其实VINS代码中也可以使用普通的针孔相机模型。这里有一个细节提一下,我觉得还蛮重要的,视觉残差的公式是归一化相机平面坐标下的误差(而不是直接使用像素误差,你发现了吗?),主要的原因还是精度问题,像素的刻度是一个像素(也就是说误差最小是1个像素变化),而归一化相机平面的刻度没有具体限制,精度更高。
(3) Marginalization
这一部分借鉴博客:http://blog.csdn.net/q597967420/article/details/76099443
sliding windowsbounding边界化了优化问题中pose的个数, 从而防止pose和特征的个数随时间不断增加, 使得优化问题始终在一个有限的复杂度内, 不会随时间不断增长。然而, 将pose移出windows时, 有些约束会被丢弃掉, 这样势必会导致求解的精度下降, 而且当MAV进行一些退化运动(如: 匀速运动)时, 没有历史信息做约束的话是无法求解的. 所以, 在移出位姿或特征的时候, 需要将相关联的约束转变成一个约束项作为prior放到优化问题中. 这就是marginalization要做的事情。
VINS-MONO中,为了处理一些悬停的case,引入了一个two-way marginalization, 简单来说就是:如果倒数第二帧是关键帧, 则将最旧的pose移出sliding window, 将最旧帧相关联的视觉和惯性数据边缘化掉,也就是MARGIN_OLD,作为一部分先验值,如果倒数第二帧不是关键帧, 则将倒数第二帧pose移出sliding window,将倒数第二帧的视觉观测值直接舍弃,保留相关联的IMU数据, 也就是MARGIN_NEW。选取关键帧的策略是视差足够大,在悬停等运动较小的情况下, 会频繁的MARGIN_NEW, 这样也就保留了那些比较旧但是视差比较大的pose. 这种情况如果一直MARGIN_OLD的话, 视觉约束不够强, 状态估计会受IMU积分误差影响, 具有较大的累积误差。
边缘化部分可以理解成是系统的先验,也就是滑窗之前的约束,这部分的约束会越来越多,矩阵的维度和耗时会越来越大。
到这里整体VINS理论的框架基本上算是介绍完毕了,对于后面的重定位,全局位姿优化和回环检测等有时间再做下讨论,现在有没有一个比较清晰的思路?如果还比较困惑的话,那就赶紧进行下面的代码实战环节吧。下面就从代码角度来分析VINS的整个第二部分。
(4)单目视觉雅可比计算(参考贺大佬)
视觉SLAM十四讲中第162页有提到,将空间坐标系下的3D点投影到像素坐标系下做最小二乘,求出该最小二乘模型的雅各比矩阵既可以得到高斯牛顿或者LM方法的下降梯度,从而优化位姿和路标点,具体的内容请参照书本。需要注意的是VINS在计算视觉雅各比时与书上有三点不同:
①VINS中由feature_tracker传过来的像素点坐标吸收了内参K且做了归一化,因此是吸收内参的归一化图像坐标。
②VINS中使用Q旋转四元数来优化位姿,因此在计算位姿对应的雅各比矩阵时和书上的公式不完全相同。
③VINS是基于滑动窗口,优化的位姿包含滑动窗口中的11帧位姿,但同时是依靠特征点来确定所优化哪两帧的位姿,每次传入视觉残差模型是遍历特征点来确定的,设定i帧为最开始观测到次特征点的相机,则j(不等于i)就为其他共视关键帧。
4.1视觉j帧残差计算(其实也可以计算i帧残差,过程基本相似)
明白上面三个不同点就可以进行下面的公式推导了,首先下图是残差计算模型,VINS选取的是j帧图像的残差计算模型。

4.2整体雅各比公式
传入到上面的j帧视觉残差模型的优化状态量分别是7维的i帧位姿,7维的j帧位姿,7维的相机和IMU外参数以及1为的特征点逆深度。因此需要计算的雅各比如下图所示:

VINS系统的所有结果的参考坐标都是世界坐标,同时都是对应IMU时刻在世界坐标系下的旋转,平移,速度等,而且逆深度的值时相对于i时刻的相机,因此我们需要整理4.1得到的i时刻的关键帧对应到j时刻的归一化相机坐标Pj的重投影方程如下图所示:(我们需要求的是Pj对于i、j时刻关键帧,相机外参以及i时刻的逆深度,所以需要构建这样一个重投影方程,才能满足偏导数求解)

由最终的公式可以看到Pj由i,j时刻的位姿(旋转和平移),相机外参(旋转和平移)以及逆深度表示,下面可以直接求雅各比(偏导数)。
4.3视觉i帧的状态量(位移和旋转)在Pj下的雅各比
这里和视觉SLAM十四讲中有出入,但是解算原理基本相同,利用了旋转四元数和差乘的性质。得到下面的偏导后整个J[0]就可以相乘得到了。

4.4视觉j帧的状态量、相机和IMU之间外参数(位移和旋转)在Pj下的雅各比
这里的雅各比推导过程就不重复了,和上面的过程相似,就直接给结果了

4.6特征点你深度在Pj下的雅各比
逆深度求偏导就比较简单了,就是一个反函数求偏导过程,得到下面的偏导后整个J[3]就可以相乘得到了。

至此,整个基于滑动窗口的视觉残差和雅各比模型就完成了。其协方差矩阵较为简单,代码中直接赋值即可,不需要计算。
第二部分的系统入口是estimator_node.cpp,(整体介绍未完待续)
1. estimator_node.cpp系统入口
首先初始化设置节点vins_estimator,同时读取参数和设置相应的参数,为节点发布相应的话题,为节点订阅三个话题,分别用来接收和保存IMU数据、图像特征数据和原始图像数据,分别是在三个回调函数中imu_callback、feature_callback和raw_image_callback,每当订阅的节点由数据送过来就会进入到相应的回调函数中。
(1) 接收IMU数据
imu_callback函数中首先执行imu_buf.push(imu_msg);将IMU数据保存到imu_buf中,同时执行con.notify_one();唤醒作用于process线程中的获取观测值数据的函数,这里唤醒以及互斥锁的作用很重要到下面真正要使用的时候在详细讨论,然后预测未考虑观测噪声的p、v、q值,同时将发布最新的IMU测量值消息(pvq值),这里计算得到的pvq是估计值,注意是没有观测噪声和偏置的结果,作用是与下面预积分计算得到的pvq(考虑了观测噪声和偏置)做差得到残差。
(2) 接收原始图像和图像特征点数据
feature_callback和raw_image_callback函数中主要是将特征数据和原始图像数据分别保存到feature_buf和image_buf中,在feature_callback也用到了con.notify_one()和互斥锁;。
2. process()处理观测值数据线程
(1) 得到观测值(IMU数据和图像特征点数据)
定义观测值数据类measurements,包含了一组IMU数据和一帧图像数据的组合的容器,这里比较有意思的是使用了互斥锁和条件等待的功能,互斥锁用来锁住当前代码段,条件等待是等待上面两个接收数据完成就会被唤醒,然后从imu_buf和feature_buf中提取观测数据measurements = getMeasurements(),需要注意的是在提取观测值数据的时候用到的互斥锁会锁住imu_buf和feature_buf等到提取完成才释放,也就是说在提取的过程中上面两个回调函数是无法接收数据的,同时上面两个回调函数接收数据的时候也使用了互斥锁,锁住了imu_buf和feature_buf,这里也不能提取imu_buf和feature_buf中的数据。因此整个数据获取的过程是:回调函数接收数据,接收完一组数据唤醒提取数据的线程,提取数据的线程提取完数据后,回调函数就可以继续接收数据,依次往复。这就是线程间通信的曼妙啊!
1) getMeasurements()返回观测值数据
函数的作用顾名思义,就是得到一组IMU数据和图像特征数据组合的容器。首先保证存在IMU数据和图像特征数据,然后还要判断图像特征数据和IMU数据是否对齐。这里使用的是队列数据结构(先进先出front是先进的数据,back是后进的数据),需要满足两个条件就能保证数据对齐,第一是IMU最后一个数据的时间要大于图像特征最开始数据的时间,第二是IMU最开始数据的时间要小于图像特征最开始数据的时间。满足数据对齐就可以数据从队列中按对齐的方式取出来。这里知道把缓存中的图像特征数据或者IMU数据取完,才能够跳出此函数,返回数据。
(2) 处理IMU数据和图像特征数据
步骤1:处理IMU数据
遍历调用send_imu(imu_msg)将单个IMU数据的dt,线加速度值和角加速度值计算出来送给优化器处理,优化器调用estimator.processIMU(dt, Vector3d(dx, dy, dz), Vector3d(rx, ry,rz));方法。
1)Estimator::processIMU(doubledt, const Vector3d &linear_acceleration, const Vector3d&angular_velocity)处理IMU数据方法
步骤1调用imu的预积分,调用push_back函数,函数中将时间,加速度和角速度分别存入相应的缓存中,同时调用了propagation函数 ,计算对应的状态量、协方差和雅可比矩阵
①propagate(double _dt, const Eigen::Vector3d &_acc_1, constEigen::Vector3d &_gyr_1)
预积分传播方程,在预积分传播方程propagate中使用中点积分方法midPointIntegration计算预积分的测量值,中点积分法中主要包含两个部分,分别是得到状态变化量result_delta_q,result_delta_p,result_delta_v,result_linearized_ba,result_linearized_bg和得到跟新协方差矩阵和雅可比矩阵(注意,虽然得到了雅各比矩阵和协方差矩阵,但是还没有求残差和修正偏置一阶项的状态变量),由于使用的是中点积分,所以需要上一个时刻的IMU数据,包括测量值加速度和角速度以及状态变化量,初始值由构造函数提供。需要注意的是这里定义的delta_p等是累积的变化量,也就是说是从i时刻到当前时刻的变化量,这个才是最终要求的结果(为修正偏置一阶项),而result_delta_q等只是一个暂时的变量,最后残差和雅可比矩阵、协方差矩阵保存在pre_integrations中,还有一个函数这里暂时还没有用到,是在优化的时候才被调用的,但是其属于预积分的内容,evaluate函数在这个函数里面进行了状态变化量的偏置一阶修正以及残差的计算。
步骤2预积分公式(3)未考虑误差,提供imu计算的当前旋转,位置,速度,作为优化的初值
步骤2:处理图像特征数据
这里进来的数据不是图像数据哦,而是前面已经跟踪匹配好的归一化平面坐标。将当前帧的特征存放在image中,image的第一个元素类型是特征点的编号,第二个元素是相机编号,第三个是特征点坐标,然后直接进入到处理图像特征数据的线程中estimator.processImage(image, img_msg->header)。
1)Estimator::processImage(constmap<int, vector<pair<int, Vector3d>>> &image, conststd_msgs::Header &header)处理图像特征数据方法
首先对进来的图像特征数据根据视差判断是否是关键帧,选择丢弃当前帧(但保留IMU数据)或者丢弃滑动窗口中最老的一帧。
步骤1:将图像数据和时间存到图像帧类中:首先将数据和时间保存到图像帧的对象imageframe中(ImageFrame对象中包含特征点,时间,位姿R,t,预积分对象pre_integration,是否是关键帧),同时将临时的预积分值保存到此对象中(这里的临时预积分初值就是在前面IMU预积分的时候计算的),然后将图像帧的对象imageframe保存到all_image_frame对象中(imageframe的容器),更新临时预积分初始值。
步骤2:标定相机和IMU的外参数:接着如果没有外部参数就标定外部参数,参数传递有的话就跳过这一步(默认有,如果是自己的设备,可以设置为2对外参进行在线标定)。
步骤3:初始化系统同时进行BA优化:当求解器处于可初始化状态时(初始状态是可初始化,初始化成功就设置为不可初始化状态),判断当前frame_count是否达到WINDOW_SIZE,确保有足够的frame参与初始化,这里的frame_count是滑动窗口中图像帧的数量,一开始被初始化为0,滑动窗口总帧数是10。有外部参数同时当前帧时间戳大于初始化时间戳0.1秒,就进行初始化操作。
步骤3.1:initialStructure()系统初始化,首先初始化Vision-only SFM,然后初始化Visual-Inertial Alignment,构成整个初始化过程。
①保证IMU充分运动,通过线加速度判断,一开始通过线加速度的标准差(离散程度)判断保证IMU充分运动,加速度标准差大于0.25则代表imu充分激励,足够初始化。
②纯视觉初始化,对SlidingWindow中的图像帧和相机姿态求解sfm问题,这里解决的是关键帧的位姿和特征点坐标。
步骤1.首先构建SFMFeature对象sfm_f,SFMFeature数组中包含了特征点状态(是否被三角化),id,2d点,3d坐标以及深度,将特征管理器中的特征信息保存到SFMFeature对象sfm_f中sfm_f.push_back(tmp_feature)。
步骤2.接着由对极约束中的F矩阵恢复出R、t,主要调用方法relativePose(relative_R, relative_T, l)。relativePose方法中首先通过FeatureManeger获取(滑动窗口中)第i帧和最后一帧的特征匹配corres,当corres匹配足够大时,考察最新的keyFrame和slidingwindow中某个keyFrame之间有足够feature匹配和足够大的视差(id为l=i),满足这两个条件,然后这两帧之间通过五点法恢复出R,t并且三角化出3D的特征点feature point,这里是使用solveRelativeRT(corres, relative_R, relative_T),solveRelativeRT方法定义在solv_5pts.cpp类中,由对极约束中的F矩阵恢复出R、t,直接调用opencv中的方法,没什么好说的,这里值得注意的是,这种relativePose得到的位姿是第l帧的,第l帧的筛选是从第一帧开始到滑动窗口所有帧中一开始满足平均视差足够大的帧,这里的第l帧会作为参考帧到下面的全局SFM使用。到这里就已经得到图像的特征点2d坐标的提取,相机第l帧和最后一帧之间的旋转和平移(注意暂时还没有得到特征的3d点坐标),有了这些信息就可以构建全局的SFM类GlobalSFM sfm,在这里调用sfm.construct(frame_count + 1, Q, T, l,relative_R, relative_T,sfm_f,sfm_tracked_points),这里以第l帧作为参考帧,在进行PNP求解之前,需要判断当前帧数要大于第l帧,这保证了第l帧直接跳过PNP步骤,首先执行下面的第l帧和最后一帧的三角化,得到共视的特征点,供下面第l+1帧和最后一帧求解PNP,然后利用pnp求解l+1帧到最后一帧的位姿R_initial,P_initial,最后的位姿都保存在Pose中,一次循环,得到l+1,l+2…n-1帧的位姿。跳出步骤2 的循环后,至此得到了l+1,l+2…n-1帧的位姿以及l+1,l+2…帧与n-1帧的特征点三角化。然后再三角化l帧和i帧(在第l帧和最后一帧之间的帧)之间的3d坐标,(这里不明白为什么要做两次,是可以三角化出更多的特征点吗????),接着PNP求解l-1,l-2…0帧和l帧之间的位姿已经三角化相应的特征点坐标,最后三角化其他所有的特征点。至此得到了滑动窗口中所有相机的位姿以及特征点的3d坐标。第6部就是进行BA优化,使用的是ceres优化位姿和特征点,这里可以参考视觉SLAM第十讲中的内容,优化方式相同。
步骤4:visualInitialAlign中调用VisualIMUAlignment方法,真正的视觉惯性联合初始化,imu与视觉对齐,获取绝对尺度等。这个方法定义在initial/initial_alignment.h中。
步骤4.1:solveGyroscopeBias计算陀螺仪偏置,整个方法的计算模型由论文中给出,使用LTLD方法求解最小二乘问题,delta_bg = A.ldlt().solve(b);这里A +=tmp_A.transpose() * tmp_A,b += tmp_A.transpose() * tmp_b,其实就是处理AT*A*x=AT*b问题,一般的最小二乘问题直接处理Ax=b也就是Ax-b=0即可,这里是使用LDLT方法,两边同乘以A矩阵的转置得到的AT*A一定是可逆的,因此就可以直接两边同乘以其逆即可,相应的说明详见LDLT方法。得到陀螺仪偏置之后将其值保存到前面定义的Bgs[]中,最后在重新计算一次预积分。
步骤4.2:LinearAlignment计算尺度,重力加速度和速度。论文中给出的公式是相邻两个速度的模型,映射到整个n+1个速度模型中,A矩阵一定是一个正定矩阵(实对称矩阵),代码中定义的A和b即是最总的H和b,tmp_A和tmp_b相邻速度间的临时变量。最后的求解方法:x = A.ldlt().solve(b);然后调用RefineGravity重新计算重力加速度方向,得到最优解。
步骤4.3:将所有的状态量由相机坐标C0转换到世界坐标W下,这里世界坐标系的定义是根据重力加速度的方向和初始相机C0坐标系的方向定义的R0 = Utility::ypr2R(Eigen::Vector3d{-yaw, 0, 0}) * R0; 定义的rot_diff就是坐标旋转矩阵q_wc0。最后将Ps[i]、Rs[i]和Vs[i]由相机C0坐标系旋转到定义的世界坐标下,这里需要说明,一般的SLAM系统世界坐标系即是C0坐标系,这里自定义了一个世界坐标系,那么最后得到的结果都是以这个世界坐标系为参考,如果想要和真值进行比较就需要注意坐标系问题了。
2) 基于滑动窗口的紧耦合优化
这部分主要是在solveOdometry()和slideWindow()方法中,当初始化完成后就会调用这两个方法。
步骤1:solveOdometry()进行BA优化,在内部调用了BA优化的方法optimization()
步骤1.未完待续
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)