如何轻松写出正确的链表代码?
1、理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
p->next=q: p 结点中的 next 指针存储了 q 结点的内存地址。
p->next=p->next->next: p 结点的 next 指针存储了 p 结点的下下一个结点的内存地址。
2、警惕指针丢失和内存泄漏
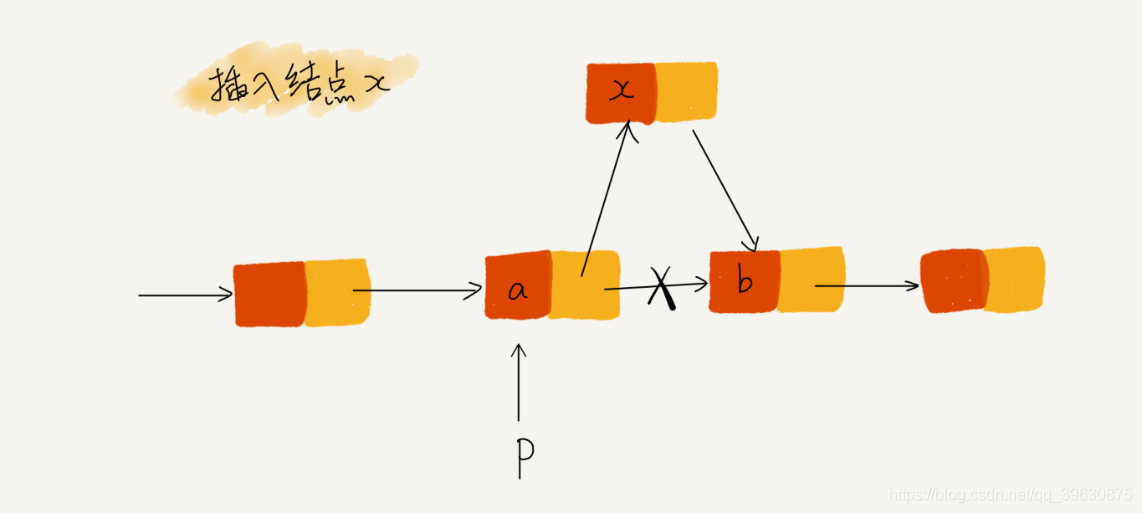
p->next = x;
\quad \quad
// 将p的next指针指向x结点, p 结点中的 next 指针存储了 x 结点的内存地址;
x->next = p->next; // x的结点的next指针存储p结点的下一个节点的内存地址,即x的内存地址,自己指向自己。因此,整个链表也就断成了两半,从结点 b 往后的所有结点都无法访问到了;
正确的应该为:要先将结点 x 的 next 指针指向结点 b,再把结点 a 的 next 指针指向结点 x,这样才不会丢失指针,导致内存泄漏
x->next = p->next;
p->next = x;
3、利用哨兵简化实现难度
针对链表的插入、删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理
① 在结点 p 后面插入一个新的结点:
new_node->next = p->next;
p->next = new_node;
② 向一个空链表中插入第一个结点
if (head == null) {
head = new_node;
}
③ 单链表结点删除操作:删除结点 p 的后继结点
p->next = p->next->next;
④ 要删除链表中的最后一个结点
if (head->next == null) {
head = null;
}
head=null 表示链表中没有结点了。其中 head 表示头结点指针,指向链表中的第一个结点。
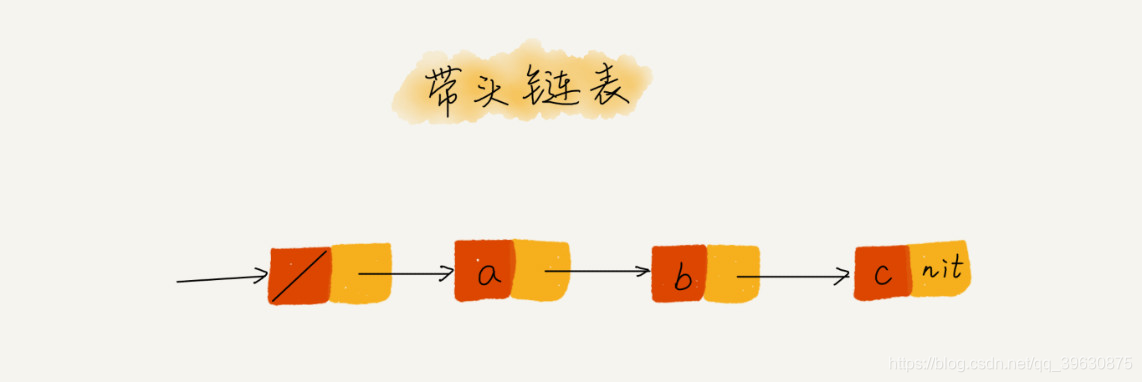
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。
带头链表: 你可以发现,哨兵结点是不存储数据的。因为哨兵结点一直存在,所以插入第一个结点和插入其他结点,删除最后一个结点和删除其他结点,都可以统一为相同的代码实现逻辑了。
4、重点留意边界条件处理
检查链表代码是否正确的边界条件有这样几个:
① 如果链表为空时,代码是否能正常工作?
② 如果链表只包含一个结点时,代码是否能正常工作?
③ 如果链表只包含两个结点时,代码是否能正常工作?
④ 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
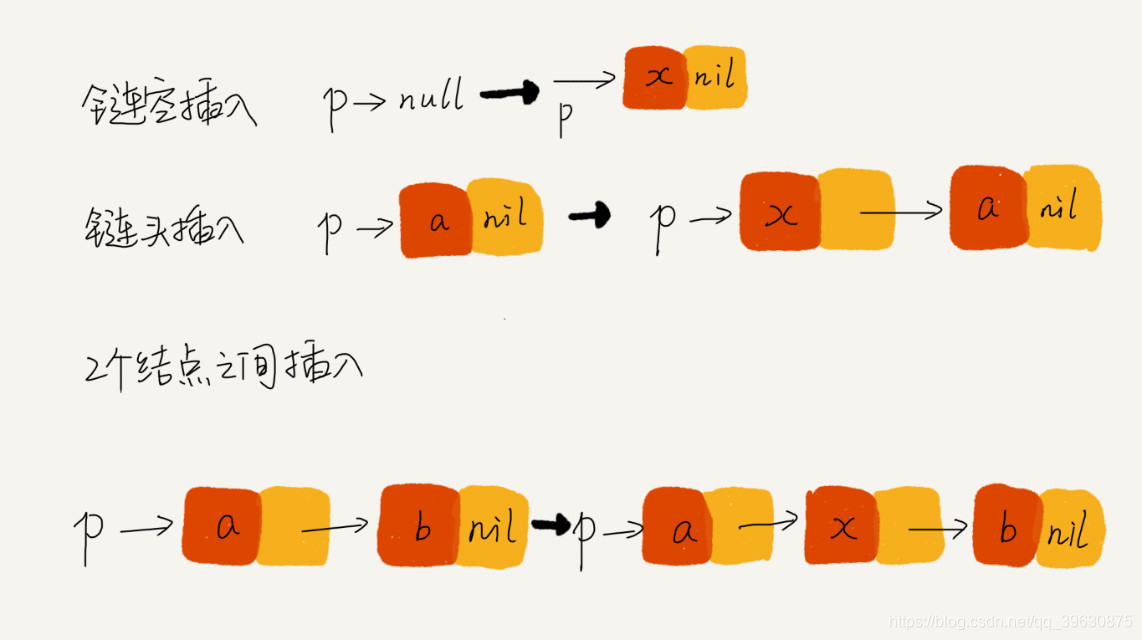
5、举例画图,辅助思考
单链表中插入一个数据:
6、多写多练,没有捷径
5个常见的链表操作:
① 单链表反转
② 链表中环的检测
③ 两个有序链表合并
④ 删除链表倒数第n个节点
⑤ 求链表的中间节点
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)