
目录
摘要:
一、介绍
二、相关工作
三、Skill-Concept Composition in VQA
四、方法
4.1. Concept Grounding
4.2. Skill Matching
4.3. Training Procedure
五、实验
5.1. Novel Skill-Concept Composition VQA
5.2. Novel-Concept VQA
5.3. Analysis
六、结论
摘要:
对数据分布不同的数据集的泛化一直是VQA任务的困难所在,为了衡量模型对新问题的泛化能力,作者将问题分为技能和概念两个部分,技能是指视觉任务,例如计数、属性识别,表示你要做一个什么样的任务,概念是指对谁做任务,例如对杯子计数,对桌子识别是什么颜色。健壮的VQA模型应该能够以新的方式去组合技能和概念,即使在训练中没有出现过这些组合,但是作者证明,现有的模型在处理新组合方面有许多需要改进的地方。作者提出了一种学习组合技能和概念的新方法,该方法通过学习grounded的概念表征,并将技能编码从概念编码中分离出来,将这两部分隐式的分离在一个模型中。作者用一种新的对比学习方法来强化这些属性,不依赖外部注释,可以从未标记的图像问题对中学习。
一、介绍

当人类回答问题时,我们首先解释问题,将其内容分解为多个部分(如概念、关系、动作、问题类型),然后选择并执行必要的技能(或计划/程序),以根据这些信息和相关的知识库(如图片)生成答案。生成答案所需的技能是一般性的,可以应用于(与)许多类型的特定问题内容,例如,如果一个人能够回答关于各种物体的“颜色”的问题,同时能够识别和回答关于“汽车”的问题,那么诸如“汽车是什么颜色的?”这个问题的答案应该是直截了当的,即使这个具体的组成部分还没有被看到(如图1)。这种用技能无缝地适应和组合概念表征的能力,对VQA真正理解和学习从较少标注的数据中归纳总结至关重要。
虽然在标准的VQA测试基准上已经取得了很大的进展,以获得更好的性能,但这些模型在设计时没有任何内置的组合概念,并且倾向于将技能和概念纠缠在学习的表示中。前人研究了VQA模型泛化能力不足的问题,并利用训练数据中不同答案分布的测试分割集对模型进行了评价。然而,这种测量方法缺乏可组合性的评估,这表明它本身缺乏泛化能力和过度依赖语言先验。
为了解决这些问题,作者的第一个贡献是VQA组合的新观点,称为技能-概念组合,和一个新的评估设置,直接针对VQA模型如何可以概括到技能和概念的新组合。要回答一个关于真实图像的自然问题,需要理解两个不同的元素:1)问题所涉及的视觉概念,例如桌子、人等等;2)我们需要从引用的概念中提取什么信息,例如提取桌子的大小信息,还是人的数量信息等等。作者在第3节中对此进行了说明,并使用该设置评估了许多VQA体系结构,并证明了现有模型在回答新问题方面还有很多需要改进的地方。
作者提出了一种改进泛化的新方法,利用对比学习在模型的内部表示中分离技能和概念,同时联合学习回答问题。我们使用grounding(就相当于事先将概念标记出来,不需要考虑上下文,就可以直接看到这个概念)作为分离概念的代理,这样模型就可以学习在问题和图像中识别一个概念,而不考虑特定的上下文。类似于弱监督grounding,作者通过对比被mask掉的概念词的多模态表征和其他问题中单词的多模态表征,训练模型恢复给定图像-问题对中提到的概念。利用一种新方法,为对比损失设计正面和负面的样本,这样模型就可以根据相关的视觉信息而不是使用表面的上下文线索来预测概念。此外,我们的方法通过对比具有相同或不同技能的问题表示,学习将技能从概念中分离出来。在最先进的模型之上,这些属性与VQA目标一起学习,并可推广到新的体系结构。
作者的方法的一些优点是:1)我们只使用VQA数据,而不使用外部注释,以一种自监督的方式学习grounding知识。这与以前的方法形成了鲜明的对比,以前的方法具有类似的目标,但由于需要事先注释需求而产生了大量的成本。2)我们的方法不依赖于答案标签来学习技能-概念分离,所以我们能够使用unlabeled igmage-question对来学习这些属性。因此,我们能够获得新的概念,并学会回答有关它们的问题,而不用用这些概念标记数据,这对于推广到一个新的领域或新的实例是关键的。
本文的主要贡献是:1)提出了一种新的VQA模型的组合性的观点和评价设置,称为技能-概念组合,它使VQA模型在真实图像的问题回答中能够得到更直接和可解释的评价。2)提出了一种新的对比学习方法,将有监督的VQA目标与自监督学习相结合,在不增加标注成本的情况下实现技能-概念的分解。3)与现有模型相比,我们的方法在新技能-概念组合上有了显著的改进,并将其推广到包含未知概念的未标记图像-问题对上。
二、相关工作
作者的工作评估的是技能和概念的组合泛化,评估的是看不见的技能和概念的组合。现有的评估泛化的工作并没有探讨对这类新目标的泛化。
CLEVR和GQA两个数据集都提供组合问题,这意味着问题涉及各种关系链(例如,“桌子上碗左边的苹果是什么颜色?”)。虽然GQA不关注新的组合,但CLEVR确实研究了属性和对象的新组合,例如,模型在训练中看到特定颜色的立方体和其他颜色的圆柱体,然后在测试中,立方体和圆柱体的颜色互换,还有一些工作是创建组合模型来处理关系推理链。我们的方法在最先进的多模态transformer架构中隐式地学习组合能力,而不是像这些方法那样明确地学习,我们还提供了关于当前的组合模型(即神经模块网络)如何能很好地推广到新问题的结果。
Grounding Visual Concepts 视觉grounding通常是研究image-caption对,以往关于视觉grounding的研究往往以弱监督的方式学习grounding,有时还会利用对比学习技术。然而,出现在VQA问题中的grounding概念在之前的工作中研究得较少。在VQA中,与视觉grounding相关的一个方向是学习具有可解释视觉注意的VQA模型,然而,这些方法通常依赖于人类对VQA答案预测中最具影响力的区域的注释,这一方法获取成本高昂,且不直接将概念与视觉区域联系起来。我们的工作学习了在问题中提到的概念,这促进了复合VQA建模,并且不使用任何额外的注释。
三、Skill-Concept Composition in VQA

我们提出了一种新颖的VQA构图观,称为技能-概念构图(图2),概念是指物体和其他基于视觉的单词或短语,技能是在回答有关真实世界图像的常见问题时所涉及的高级视觉推理过程的集合。这些技能对概念进行操作,根据输入/输出表示的复杂性和必要的推理过程而有所不同。我们对这些技能的分类提取自VQA v2问题的一个子集的注释,以及从VQA之前的工作中获得的灵感,技能通常是相互独立的。
我们对这些VQA技能做了一个重要而直观的观察:为了回答一个问题,通常只需要对图(图2)中的一个或多个概念应用少量的技能(通常是一个)。这个观察提供了一个对out-of-distribution数据可判断的视图模型的泛化能力:一个模型应该学习一项技能是一个分离的过程,可以应用于不同的概念。这种明确的技能-概念分离的概念构成了本文的贡献,包括将在下文中介绍的一种新的novel-VQA评估方法,以及一个可以回答新问题的VQA模型的新框架(第4节)。
Novel-VQA Evaluation 在实验中,评估了两个novel-vqa设置:1)回答关于技能和概念的新组合的问题;2)回答关于模型以前没有任何答案的概念的问题。
Comparison to Existing Evaluations 我们的评估指标不同于现有的VQA基准,后者也旨在衡量VQA模型的泛化能力。没有一个基准像我们的评估指标那样直接处理和评估技能概念的组合性。
四、方法
Preliminaries 作者建立在一个基本的VQA设置之上,包括特征提取、表示、multi modal encoder 分类预测等以学习技能-概念分离,并独特地利用标记数据和未标记数据。
Overview 我们的目标是学习可分离的技能和概念,以便我们可以组合它们来回答新的问题。要做到这一点,模型应该认识到问题中提到的概念是通过它们在图像中的出现来表现的(即,grounding),而且无论问题或图像中的概念是什么,技能都应该是可识别的。收集指导来识别问题中的概念,将它们标记于图像中,并用技能标记问题将是非常昂贵的。因此,我们使用对比学习以一种自监督的方式学习技能-概念分离。如图3所示,将两个额外的对比目标与VQA目标一起训练模型:概念grounding(4.1节),学习grounding的概念表征;技能匹配(4.2节),对技能的概念性表征进行编码。对于我们的每一个目标,模型都有目标样本和一个参考集,从精心策划的候选参考集中取样的积极和消极的样本。每个目标都训练模型,使目标样本的表示与积极样本的表示相似。在第4.3节中,我们与VQA共同阐述了我们学习这些目标的训练程序。函数/设置具体细节在附录b中。

4.1. Concept Grounding
为了学习概念的有根据表征,我们将目标问题中提到的概念隐藏起来,然后利用多模态上下文信息,通过指向参考集中例子中提到的相同概念,训练模型恢复提到的概念(图3)。
Concept Discovery 我们首先确定可以在图像中grounded的概念词(就是概念显式的出现在图像上),虽然这可以通过不同的方法实现,但我们只是使用启发式。我们使用词性标记和lemmatization来识别VQA v2中最常见的400个名词,然后过滤掉无法grounded的概念(例如,“时间”)。对于一个给定的问题Q,我们想找到一些例子,这些例子会同时提到一个概念以及这个概念在图像中的出现,如果一个关于图像的问题提到了一个概念,那么这个概念可能会出现在图像中。因此,我们确定一组问题,提到相同的概念C,称之为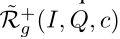 ,我们认为这是问题Q的候选的正面参考集,不提及任何相同概念的问题集被视为候选消极参考集,称之为
,我们认为这是问题Q的候选的正面参考集,不提及任何相同概念的问题集被视为候选消极参考集,称之为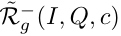 。为了增加概念出现在图像中的可能性,我们采用了一组基于NLP的启发式方法来删除图像中可能不包含该概念的问题,例如计算回答为“0”的问题。
。为了增加概念出现在图像中的可能性,我们采用了一组基于NLP的启发式方法来删除图像中可能不包含该概念的问题,例如计算回答为“0”的问题。

Concept-Context Contrastive (CCC) References 给定一个目标问题Q和一个目标概念c,在Q中,我们可以简单地通过从和随机抽样正负样本来创建参考集,仅基于问题是否包含目标概念c。然而,我们提出了一种新的参考示例过滤策略来鼓励概念基础。我们的动机是,在VQA训练期间,一个概念通常与某些类型的视觉场景或语言先验知识同时出现。因此,正面和负面的例子应该迫使模型在与目标例子对比时不依赖表面的线索,而是看正确的视觉区域。我们的解决方案是建立一组精确的参考候选集,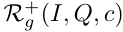 和
和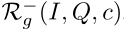 ,用于每个(I,Q,c)元组,以确保数据集中存在的共现因子可以减少。如图4所示,我们希望找到积极的例子,这些例子也包含“树”的概念,但具有不同的视觉场景和来自目标的问题。对于负面例子,我们寻找在问题或视觉场景方面与目标相似的干扰物(例如,图4中有滑雪者的山脉),但不参考“树”。为了实现这一点,我们首先通过mask掉问题来表示上下文,并将mask掉的问题和图像输入现成的特征提取器,以获得问题上下文表示q和图像表示v,我们通过以下方式衡量上下文相似性:
,用于每个(I,Q,c)元组,以确保数据集中存在的共现因子可以减少。如图4所示,我们希望找到积极的例子,这些例子也包含“树”的概念,但具有不同的视觉场景和来自目标的问题。对于负面例子,我们寻找在问题或视觉场景方面与目标相似的干扰物(例如,图4中有滑雪者的山脉),但不参考“树”。为了实现这一点,我们首先通过mask掉问题来表示上下文,并将mask掉的问题和图像输入现成的特征提取器,以获得问题上下文表示q和图像表示v,我们通过以下方式衡量上下文相似性:

其中β是标量,(v,q)和(v',q')分别是来自目标和候选示例的表示。
为了从中选择正例,我们使用β=0.6,并抽样一组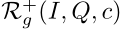 N+个例子,使ξ最小化,作为(I,Q,c)的候选正例。对于负例,我们应用两个β设置,最大化ξ:β=0.7,有利于文本更相似的示例;β=0.3,有利于具有相似视觉背景的图像。对于每一个设置,我们从
N+个例子,使ξ最小化,作为(I,Q,c)的候选正例。对于负例,我们应用两个β设置,最大化ξ:β=0.7,有利于文本更相似的示例;β=0.3,有利于具有相似视觉背景的图像。对于每一个设置,我们从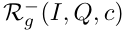 中选择N-个例子,如图4所示,当从这两组候选样本中取样参考集时,例子鼓励模型学习问题中提到的概念与其在图像中的外观之间的特定对应关系。直观地说,模型必须学会在干扰因素存在的情况下为所提及的概念学习ground。
中选择N-个例子,如图4所示,当从这两组候选样本中取样参考集时,例子鼓励模型学习问题中提到的概念与其在图像中的外观之间的特定对应关系。直观地说,模型必须学会在干扰因素存在的情况下为所提及的概念学习ground。
Concept Grounding Loss 让(I,Q)和c分别作为目标示例和目标概念,让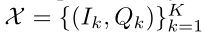 作为参考集。k*是从中抽取的x中的正例的索引,而其他k−1示例是R中的否定示例。wi是指概念的token,我们将这个问题的mask版本和相应的图像一起输入到模型f中,f输出多模态表示,我们从中提取mask概念token的表示hi,接下来,我们分别将x中的示例输入到模型中,以获得每个token表示
作为参考集。k*是从中抽取的x中的正例的索引,而其他k−1示例是R中的否定示例。wi是指概念的token,我们将这个问题的mask版本和相应的图像一起输入到模型f中,f输出多模态表示,我们从中提取mask概念token的表示hi,接下来,我们分别将x中的示例输入到模型中,以获得每个token表示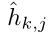 ,其中j是token在Qk中的索引。让
,其中j是token在Qk中的索引。让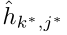 是实证问题中提到的概念的表示。我们的grounding损失是NCE目标,该目标要求模型将提及的mask概念的多模态表示与参考集中提及的相同概念的表示相匹配:
是实证问题中提到的概念的表示。我们的grounding损失是NCE目标,该目标要求模型将提及的mask概念的多模态表示与参考集中提及的相同概念的表示相匹配:

其中φg是可学习的投影函数,sim(·,·)是相似函数(例如点积或余弦相似性)。为了正确匹配hi和,模型必须对两种token表示中这些示例的图像之间匹配的视觉特征进行编码。我们的CCC参考集鼓励正面示例中提到的概念和masked概念的这些表示基于正确的视觉区域,因为模型不能依赖于表面的文本或视觉共现。
4.2. Skill Matching
与视觉概念相反,回答某个问题所需的基本技能在很大程度上独立于图像外观和问题中提到的概念。例如,计数问题应该共享一个类似的过程来生成答案:对与计数主题相关的图像区域进行总结,以进行计数预测。这个过程应该独立于被询问对象的类型。换句话说,我们试图学习问题的总结表示,这些问题共享推断答案的基本步骤,并且对概念保持不变。
Skill References 学习技能的一种简单方法是对明确要求相同推理步骤的问题进行注释。该注释可在合成数据集上获得,但在涉及真实图像和问题的数据集上不可用。相反,我们建议挖掘一组对比示例,以了解哪些问题需要相同/不同的技能,并将问题与相同的技能相匹配。由于问题所需的技能通常由问题的词语表示,因此我们确定语义相似的问题。基本上,需要相同技能的问题(例如,“什么颜色…”)应该相互关联,无论问题中提到的具体概念如何。因此,对于每个问题,我们mask掉概念词,并计算了它们的BERT编码表示,对于给定的(I,Q),使用BERT表示法从前200个最相似的问题中抽取正面参考示例集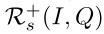 ,负面参考示例集
,负面参考示例集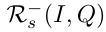 是从数据集的其余部分随机选择的。
是从数据集的其余部分随机选择的。
Skill Matching Loss 对于给定的目标示例(I,Q),让我们对目标问题进行总结表示。这可以使用特殊的输入token(如BERT)或通过对编码器输出的所有问题token表示的操作来计算。我们对图像问题对的参考集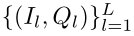 进行采样,其中正面示例从得到,与目标问题具有相同的技能,参考集的其余部分来自。设ˆhl为参考集中问题的总结表示,如图3所示,我们的技能匹配损失定义为:
进行采样,其中正面示例从得到,与目标问题具有相同的技能,参考集的其余部分来自。设ˆhl为参考集中问题的总结表示,如图3所示,我们的技能匹配损失定义为:

4.3. Training Procedure
请阅读原文。
五、实验
Data and Settings VQA v2数据集,使用VQA精度[6]对不同的新问题进行了性能比较。
Model Comparisons 列出作比较的模型。
5.1. Novel Skill-Concept Composition VQA
我们选择了VQA v2中的三种常见技能:计数、颜色查询和子类别识别。对于每一项技能,我们都会删除一个概念或一组多个概念的共同问题的数据标签,这些概念可以形成与训练不同的类别,然后对这些组成部分进行测试。概念(或概念组)以两个标准随机抽样:每个技能概念组合包含可靠数量的测试数据,以测量准确性,并且组合在整个数据集上具有不同的覆盖范围(更多详细信息见论文附录A)。

表1显示每个新组合子集的VQA精度,有趣的是,尽管神经模块网络被设计为明确地将问答过程分解为子任务,原则上这有助于使这些子任务适应新问题,从而更好地概括,但它们产生的性能低于transformer模型,这可能是由于自我注意机制的有效特征学习能力。在所有transformer模型中,我们的基础编码器实现了与现有网络的竞争性能,表明它是多模态transformer中的一个强大基线。我们的对比学习框架优于基线和所有其他方法,这支持了我们的框架对新组合的有效性。
5.2. Novel-Concept VQA

对于这个实验,我们感兴趣的是这样一种环境:模型从未接受过回答有关概念问题的训练,但可以利用未标记的图像问题对,然后在提到这个给定概念的问题上进行测试。与之前的实验类似,对这些概念进行抽样,以最大限度地扩大覆盖范围并保持合理的测试规模。此设置比之前的实验更具挑战性,因为模型忽略了对任何具有给定概念的问题的VQA训练监督,而不是同时具有给定概念和特定技能的问题。我们在附录E中提供了新概念VQA的定性示例,并在表格B中报告了定量结果。对于这种更具挑战性的新颖问答设置,平均而言,两种现有transformer架构的性能明显低于其他模型。这可能表明transformer体系结构在大规模的视觉和语言预训练中表现良好,可能难以专门完成VQA任务。基本模型的性能略优于神经模块网络。最后,我们的框架再次平均优于所有模型,证明了它在提高VQA对新概念的泛化能力方面的价值。
5.3. Analysis

Concept Grounding 由于我们的方法在没有强大监督的情况下学习grounding概念,因此我们希望直接测试其grounding能力。为了获得评估集,我们使用图像中与每个元组中的概念对应的可视区域手动注释320个图像问题概念元组,使用Faster RCNN找到候选视觉区域,我们使用recall@5作为我们的grounding指标,如果正确的视觉区域位于与目标概念标记最相似的前5个视觉区域内,则考虑grounding正确。使用我们的框架训练的模型实现了59.12的grounding召回。我们的框架在没有额外训练数据的情况下实现了这一改进,如图5所示,我们的模型通常可以正确地将各种对象grounding,但可能会被模糊的概念(如错误示例中的蜡烛)所愚弄。此外,学习区分几乎总是同时出现的概念(例如,“衬衫”和“人”)也是一项挑战。

Loss Ablation 我们通过抽样三个新的组成部分和三个新的概念来做消融,并在表3中报告它们的平均性能。增加我们的损失会带来持续的收益,通过我们的完整框架实现最高效果。单独使用时,我们的grounding损失似乎比技能损失带来更大的好处。尽管如此,最好的性能是通过组合这两个组件来实现的,这进一步支持了技能和概念分离的价值。我们还试验了一个(MLM)目标,以取代我们的损失,我们的目标比MLM目标表现得更好,这意味着我们的目标提供的改进不仅仅是由于额外的数据。

CCC Reference Sets 为了研究我们的CCC参考集选择策略的效果,我们将其与常用的随机抽样方法进行比较,并在表4中报告新概念VQA结果。我们用完整的框架训练两个模型,唯一的区别是概念损失的参考集构造方法,这两个模型都改进了基础模型,我们的参考集构造方法提供了更一致的收益。

Existing Benchmarks 我们还评估了VQA-CP v2和VQA v2的测试集,表5。虽然我们看到了总体上的收益,但值得注意的是,我们的方法能够在VQA-CP v2上进行改进,而不需要额外的注释、集成和调优。
六、结论
我们在VQA中提出了一个新的泛化设置:测量合成回答问题所需的技能的能力,以及应基于图像的视觉概念。我们表明,现有的方法很难推广到这两个因素的看不见的组成部分,我们提出了一种新的方法,隐式地将技能和概念分开,同时使用对比学习将概念视觉化,我们的方法能够从未标记的VQA数据中学习,以便回答有关以前未看到的概念的问题。VQA v2上的结果表明,所提出的框架可以在新的技能概念组合上实现最先进的性能,并且可以从未标记的数据中进行推广。