Scala 是一门以 java 虚拟机(JVM)为目标运行环境并将面向对象和函数式编程语言的最佳特性结合在一起的编程语言。你可以使用Scala 编写出更加精简的程序,同时充分利用并发的威力。由于scala 运行于 JVM 之上,因此它可以访问任何 Java 类库并且与 Java 框架进行相互操作。
1. Scala 解释器
1.1 安装Scala
1)、Scala 官网下载最新版本https://www.scala-lang.org/download/:scala-2.12.8.tgz;
2)、Linux 下安装 Scala tar包,修改环境变量:
$ tar -zvxf scala-2.12.8.tgz
$ vim ~/.bash_profile
SCALA_HOME=/home/scala-2.12.8
PATH=$PATH:$SCALA_HOME/bin
$ source ~/.bash_profile
$ scala
Welcome to Scala 2.12.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191).
Type in expressions for evaluation. Or try :help.
scala>
1.2 Scala:HelloWorld
1)、编写 Scala 文件
$ vim HelloWorld.scala
object HelloWorld {
def main (args: Array[String]) {
println("hello scala,hello world!")
}
}
2)、编译 Scala 文件
$ scalac HelloWorld.scala
3)、运行 .class 文件
$ scala HelloWorld
hello scala,hello world!
1.3 Scala Plugin for IDEA
1)、IDEA 首页点击 Configure——>Plugins:

2)、搜索 Scala ,点击 Install:

3)、Scala 官网下载 Windows 最新版本https://www.scala-lang.org/download/:scala-2.12.8.msi,安装过程略(系统环境变量选配);
4)、IDEA 下新建项目——>Scala——>IDEA——>Create scala sdk——>选择Browser 上述Windows下scala安装目录:
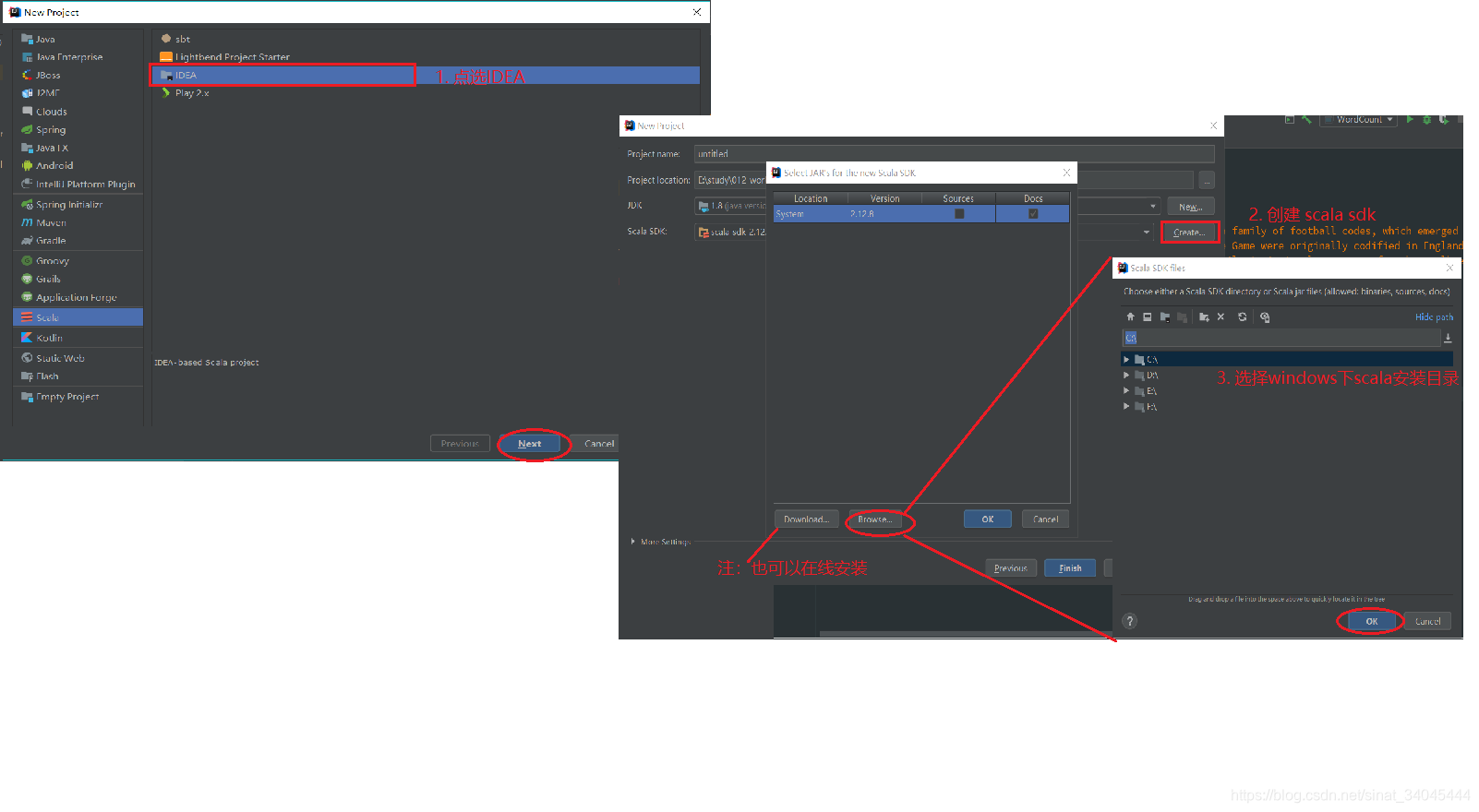
5)、为scala项目命名,点击finish。
2. Scala 基础语法
2.1 声明变量
1)、以 val 定义一个常量(无法改变其内容):
scala> val name="zhangsan"
name: String = zhangsan
scala> name="lisi"
<console>:12: error: reassignment to val
name="lisi"
^
2)、以 var 定义一个可修改值的变量:
scala> var age=20
age: Int = 20
注:在scala中,我们鼓励你使用 val ——除非你真的需要改变它的内容。
3)、多种定义变量的形式
scala> val msg:String = "hello"
msg: String = hello
scala> val msg:Any = "hello"
msg: Any = hello
scala> val msg = "hello"
msg: String = hello
4)、scala 常用类型
和 Java 一样,scala 也有7种数值类型:Byte、Char、Short、Int、Long、Double、Float,以及一个Boolean类型(注意首字母大写)。跟Java不同的是,这些类型都是类。
2.2 算术和操作符重载
Scala 的算术操作符和在 Java 中的效果是一样的:+—*/%等操作符完成的是它们通常的工作,位操作符&|^>><<也一样。只有一点特别的是:这些操作符实际上是方法,例如:
a + b
# 是如下方法调用的简写
a.+(b)
这里的+是方法名,Scala 并不会对非字母或数字的方法名有偏见。又如:
scala> 1.to(10)
# 可以写成
scala> 1 to 10
res0: scala.collection.immutable.Range.Inclusive = Range 1 to 10
2.3 控制结构
1)、条件表达式
Scala 中的if/else表达式有值,这个值就是跟在if或else之后的表达式的值:
scala> val i = 1
i: Int = 1
scala> val s = if(i > 0) 1 else -1
s: Int = 1
# 混合类型表达式的返回值类型是公共超类型 Any
scala> val s = if(i > 0) 1 else "error"
s: Any = 1
2)、语句终止
Scala 中和JavaScript 等其它脚本语言类似——行尾的位置不需要分好,若想在单行中写下多个语句可以用分号隔开。
3)、循环语句
- Scala拥有于Java和C++相同的while和do循环:
while(n > 0) {
r = r*n
n-= 1
}
for(i<- 1 to n)
r = r * i
1 to n返回数字1到数字n(含)的Range(区间);遍历字符串或数字时,往往需要使用从0 到n-1的区间,这时可以用until方法而非to方法,如遍历字符串:
val s = "Hello"
var sum = 0
for (i <- 0 until s.length)
sum += s(i)
// 等价于如下写法
for (ch <- "Hello")
sum += ch
以 变量<- 表达式 的形式提供多个生成器,用分号隔开:
scala> for (i <- 1 to 3 ; j <- 1 to 3) print((10*i+j) + " ")
11 12 13 21 22 23 31 32 33
每个生成器都可以带一个守卫,以if开头的Boolean表达式:
scala> for (i <- 1 to 3 ; j <- 1 to 3 if i!=j) print((10*i+j) + " ")
12 13 21 23 31 32
可以使用任意多的定义,引入可以在循环中使用的变量:
scala> for (i <- 1 to 3 ; form = 4-i ; j <- form to 3) print((10*i+j) + " ")
13 22 23 31 32 33
如果for循环的循环体以yield开始,则该循环会构建出一个集合,每次迭代生成集合中的一个值:
scala> var v = for( i <- 1 to 10) yield i % 3
v: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 0, 1, 2, 0, 1, 2, 0, 1)
这类循环叫做for推导式,for推导式生成的集合与它的第一个生成器是类型兼容的:
scala> for ( c <- "Hello" ; i <- 0 to 1) yield (c + i).toChar
res6: String = HIeflmlmop
scala> for ( i <- 0 to 1 ; c <- "Hello") yield (c + i).toChar
res7: scala.collection.immutable.IndexedSeq[Char] = Vector(H, e, l, l, o, I, f, m, m, p)
2.4 方法和函数
1)、方法的定义
Scala 中定义方法的格式:def 方法名( 参数1:类型,参数2:类型...):[返回值类型] = {方法体},如:
scala> def add(x:Int,y:Int):Int = x + y
add: (x: Int, y: Int)Int
# 等价于
scala> def add(x:Int,y:Int) = x + y
add: (x: Int, y: Int)Int
scala> add (1,2)
res8: Int = 3
注:在递归方法中必须指定返回值类型。
Scala 中无返回值的方法不能用 Java中的 void 修饰,而是 Unit类型:
scala> def sayHi():Unit ={
| println("Hi ~")
| }
sayHi: ()Unit
scala> sayHi()
Hi ~
# 若无参数列表也可如下方式调用
scala> sayHi
Hi ~
注:返回值无需 return 关键字修饰。
2)、函数的定义
Scala 除了方法之外还支持函数,且函数异于方法,定义函数的格式:var|val 函数名 = (参数1:类型,参数2:类型,...) => {函数体} 可以看出函数也是变量,函数可以作为参数传入到方法中;
scala> val f1 = (x:Int,y:Int) => x+y
f1: (Int, Int) => Int = $$Lambda$1435/2128513389@199efc58
scala> f1(1,2)
res11: Int = 3
3)、方法转换成函数
scala> def m1 (x:Int):Int = x*x
m1: (x: Int)Int
scala> val f1 = m1 _
f1: Int => Int = $$Lambda$1453/434672008@3a65e121
4)、变长参数
定义一个可以接受可变长度参数列表的方法会更加方便使用,如下语法:
def sum(args : Int*) = {
var result = 0
for (arg <- args) result += arg
result
}
val s1 = sum(1,3,6,4)
// 将1 to 5 当做参数序列传入
val s2 = sum(1 to 5 : _*)
2.5 数组
1)、定长数字的定义
定长数组即长度不变的数组,也就是Scala中Array:
// 定义10个整数的数组,所有元素的初始值为0
val nums = new Array[Int](10)
// 定义10个字符串元素的数组,所有元素的初始值为null
val strs = new Array[String](10)
// 定义长度为2的Array[String]并赋初始值,不需要new
val s = Array("Hello","Scala")
s{0} = "Bye" // 变为Array("Bye","Scala"),注意使用{}或()而不是[]
2)、变长数组:数组缓冲
Scala 中的变长数组就是 ArrayBuffer,使用ArrayBuffer时需要导包:
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> var ab1 = new ArrayBuffer[Int]()
ab1: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
常用操作:
import scala.collection.mutable.ArrayBuffer
// 创建一个空的数组缓冲,准备存放整数
val ab = new ArrayBuffer[Int]()
// 在数组末尾添加元素
ab += 1
// 在数组末尾添加多个元素
ab += (2,3,4,5)
// 向数组添加另一个数组或集合,使用++=
ab ++= Array(6,7,8)
// 移除指定元素,若存在多个该元素则移除第一个
ab -= 3
// 移除最后3个元素
ab.trimEnd(3)
// 以上在数组末尾添加或移除元素是一个高效操作,若是在数组中任意位置插入或移除元素并不高效
// 在索引为2处插入元素9
ab.insert(2,9)
// 在索引为2处插入多个元素
ab.insert(2,10,11,12)
// 移除索引为3处的元素
ab.remove(3)
// 移除索引为3处之后的多个元素
ab.remove(3,2)
// 数组缓冲转换为普通数组,反之使用toBuffer
ab.toArray
3)、数组遍历
val arr = Array(1,2,3,4,5,6)
for(i <- 0 until arr.length)
println(i+" ")
// 若要从数组的尾端反向遍历
for(i <- (0 until arr.length).reverse)
// 另一种遍历方式,若不需要数组索引下标,类似Java中的增强for
for(elem <- a)
println(elem)
4)、数组的转换
使用for推导式for(…) yield 循环创建了一个类型于原始集合相同的新集合:
val result = for (elem <- arr) yield 2*elem
通常在遍历一个集合时,需要处理满足特点条件的元素,可通过守卫:for中的if来实现:
val result = for (elem <- arr if elem % 2 ==0) yield 2*elem
5)、数组的常用算法
Scala 内建的求和函数:
Array(1,3,5,-1,2).sum //10
Scala 内建的求最小值最大值函数:
Array(1,3,5,-1,2).min //-1
Array("cat","mary","abc","aba").max // mary
Scala 的sorted方法,不会修改原始数组:
val ab = ArrayBuffer(2,7,4,6)
val abSort = ab.sorted(_ < _) // abSort = ArrayBuffer(2,4,6,7)
val abDescending = ab.sorted(_ > _) // abDescending = ArrayBuffer(7,6,4,2)
Scala 的内建快速排序 quickSort只能对数组排序,但不能对数组缓冲排序:
scala.util.Sorting.quickSort(Array(2,7,4,6))
Scala 数组的指定分隔符输出数组字符串:
Array(2,7,4,6).mkString(";") //"2;7;4;6"
2.6 映射和元组
1)、构造映射
Scala 中的映射相当于Java中的Map集合,我们可以这样来构造一个映射:
val scores = Map("Alice"-> 89,"Tom"-> 79,"Mary"-> 93)
上述代码构造出一个不可变的Map[String,Int],其中的值不能被改变。若想要定义一个可变映射,则用:
val scores = scala.collection.mutable.Map("Alice"-> 89,"Tom"-> 79,"Mary"-> 93)
若想要定义一个空的映射,需要选定可变映射实现并给出类型参数:
val scores = scala.collection.mutable.Map[String,Int]
在Scala中,映射就是对偶的集合,简单来说对偶就是两个值构成的组,这两个值并不一定是同一类型,如(“Alice”,89)。
2)、获取映射中的值
使用()表示法查找某个键对应的值,若该映射不包含请求的键,则会跑出异常:
val tomScore = scores("Tom")
检查映射中是否含有某个指定的键,可以用contain方法:
val tomScore = if (scores.contains("Tom")) scores("Tom") else 0
上述的另一种写法:
val tomScore = scores.getOrElse("Tom",0)
3)、更新映射中的值
在可变映射中(非可变映射无法修改值),可以修改或添加某个映射:
scores("Tom") = 99
// 用+=操作符添加多个映射关系
scores += ("Sam" -> 65 , "Jerry" -> 97)
// 用-=操作符移除某个键
scores -= "Alice"
4)、迭代映射
scala> for((k,v)<-scores) println(k+"=="+v)
Alice==89
Tom==79
Mary==93
若出于某种原因,你只需要访问键或值,将Java一样,则可以用keySet和valus方法:
scala> for(v <- scores.values) println(v)
89
79
93
若要反转一个映射,可以用:
for((k,v) <- 映射) yield (v,k)
5)、已排序映射
默认情况下,Scala给的是哈希表映射树,可以顺序的访问所有键,若得到这样一个不可变的映射树可以用:
scala> val sortedScores = scala.collection.immutable.SortedMap("Alice"-> 89,"Tom"-> 79,"Mary"-> 93)
sortedScores: scala.collection.immutable.SortedMap[String,Int] = Map(Alice -> 89, Mary -> 93, Tom -> 79)
scala> println(sortedScores)
Map(Alice -> 89, Mary -> 93, Tom -> 79)
6)、元组
映射是键/值对偶的集合,对偶是元组(tuple)的最简单形态——元组是不同类型的值得聚集。如:
scala> val tuple = (1,2.2,"333")
tuple: (Int, Double, String) = (1,2.2,333)
可以使用方法 _1 、 _2 、 _3 、…访问元组,如:
scala> val second = tuple._2
second: Double = 2.2
使用模式匹配来获取元组的组元,如:
scala> val (first,second,third) = tuple
first: Int = 1
second: Double = 2.2
third: String = 333
3. Scala 实现简易版 wordcount
3.1 Scala 命令行实现单机版单词统计
# 1.模拟数据源字符数组
scala> val lines = Array("Hello Tom where are from","Hello Jerry I am from China","Wow beautifrl country I love China")
lines: Array[String] = Array(Hello Tom where are from, Hello Jerry I am from China, Wow beautifrl country I love China)
# 2.将上述数组压平映射成一维单词数组
scala> val words = lines.flatMap(_.split(" "))
words: Array[String] = Array(Hello, Tom, where, are, from, Hello, Jerry, I, am, from, China, Wow, beautifrl, country, I, love, China)
# 3.单词和数字1映射成关系对偶
scala> val wordAndOne = words.map((_,1))
wordAndOne: Array[(String, Int)] = Array((Hello,1), (Tom,1), (where,1), (are,1), (from,1), (Hello,1), (Jerry,1), (I,1), (am,1), (from,1), (China,1), (Wow,1), (beautifrl,1), (country,1), (I,1), (love,1), (China,1))
# 4. 按单词分组
scala> val wordGrouped = wordAndOne.groupBy(_._1)
wordGrouped: scala.collection.immutable.Map[String,Array[(String, Int)]] = Map(are -> Array((are,1)), am -> Array((am,1)), China -> Array((China,1), (China,1)), Tom -> Array((Tom,1)), country -> Array((country,1)), Jerry -> Array((Jerry,1)), I -> Array((I,1), (I,1)), love -> Array((love,1)), Hello -> Array((Hello,1), (Hello,1)), beautifrl -> Array((beautifrl,1)), from -> Array((from,1), (from,1)), where -> Array((where,1)), Wow -> Array((Wow,1)))
# 5. 映射单词和组内元素长度关系,即统计单词个数
scala> val wordAndCount = wordGrouped.map(t => (t._1,t._2.length))
wordAndCount: scala.collection.immutable.Map[String,Int] = Map(are -> 1, am -> 1, China -> 2, Tom -> 1, country -> 1, Jerry -> 1, I -> 2, love -> 1, Hello -> 2, beautifrl -> 1, from -> 2, where -> 1, Wow -> 1)
# 6. 根据单词出现次数进行降序排序
scala> val result = wordAndCount.toList.sortBy(_._2).reverse
result: List[(String, Int)] = List((from,2), (Hello,2), (I,2), (China,2), (Wow,1), (where,1), (beautifrl,1), (love,1), (Jerry,1), (country,1), (Tom,1), (am,1), (are,1))
3.2 使用IDEA编写简易版wordcount Scala代码
object WordCount {
def main(args: Array[String]): Unit = {
//1.准备行数据数组
val lines: Array[String] = Array("Hello Tom where are from","Hello Jerry I am from China","Wow beautifrl country I love China")
//2.切分然后压平
val words: Array[String] = lines.flatMap(_.split(" "))
//3.将单词和数字"1"映射到一个元祖Map中
val wordAndOne: Array[(String, Int)] = words.map((_,1))
//4.分组
val grouped: Map[String, Array[(String, Int)]] = wordAndOne.groupBy(_._1)
//5.统计
// grouped.map(t=> (t._1,t._2.length))
val wordAndCount: Map[String, Int] = grouped.mapValues(_.length)
//6.排序(降序)
val result: List[(String, Int)] = wordAndCount.toList.sortBy(_._2).reverse
//7.输出结果
println(result)
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)