1011
名词解释
| 名词 | 解释 |
|---|
| POP | 面向过程编程(procedure oriented Programming) |
| OOP | 面向对象编程(object oriented programming) |
| GP | 泛型编程(generic programming) |
| 运算符重载(operator overloading) |
| 整型提升(integral promotion) |
| |
数值范围
| 类型 | 取值范围 | 加1/减1 操作 |
|---|
short
(16位) | -32768 ~ 32767
≈ 3*10的4次方 | 32767+1应该等于-32768 |
unsigned short
(16位) | 0 ~ 65535
≈ 6*10的4次方 | 0-1应该等于65535 |
int
(32位) | -2147483648 ~ 2147483647
≈ 2*10的9次方 | 2147483647+1应该等于-2147483648 |
unsigned int
(32位) | 0 ~ 4294967295
≈ 4*10的9次方 | 0-1应该等于4294967295 |
char
(8位) | -128 ~ 127 | 127+1应该等于-128 |
signed char
(8位) | -128 ~ 127 | 127+1应该等于-128 |
unsigned char
(8位) | 0 ~ 255 | 0-1应该等于255 |
long
(32位) | -2147483648 ~ 2147483647
≈ 2*10的9次方 | |
unsigned long
(32位) | 0 ~ 4294967295
≈ 4*10的9次方 | |
long long
(64位) | -9223372036854775808 ~ 9223372036854775807
≈ 9*10的18次方 | |
unsigned long long
(64位) | 0 ~ 18446744073709551615
≈ 1*10的19次方 | |
float
(32位) | | |
double
(64位) | | |
long double
(64位) | | |
| | | |
第1章 预备知识
1.1 C++简介
| 语言 | 编程方式 |
|---|
| C语言 | POP |
| C++ | POP、OOP(类class)、泛型编程(模板template) |

1.2 C++简史
1.2.2 C语言编程原理
数据是程序使用和处理的信息;而算法是程序使用的方法。

1.2.3 面向对象编程
POP强调的是算法;而OOP强调数据。
OOP三大特性:封装、继承、多态
一个类里有属性(变量)和方法(函数)。

1.2.4 C++和泛型编程
泛型编程强调独立于特定数据类型,
比如一个排序函数:有对整型数据的排序,有对浮点型数据的排序,数据类型很多,就需要写很多个针对不同数据类型的排序函数,而泛型编程可以只写一个泛型函数,并将其用于各种实际类型当中。

1.2.5 C++的起源
C++是C语言的超集,C++是包含C的,是C的扩充版本。
任何有效的C程序都是有效的C++程序。

1.3 可移植性和标准
1.3.2 本书遵循的C++标准
详尽介绍C++98,并涵盖一些C++11新增的一些特性。

1.4 程序创建的技巧
编程步骤:
1.使用文本编辑器编写程序—源代码
2.用编译器编译源代码,生成目标代码—目标代码
3.将目标代码和其他代码链接起来—链接
4.生成最终的可执行代码—可执行代码


1.4.1 创建源代码文件
扩展名:.cpp
1.4.2 编译和链接
1.UNIX编译和链接
2.Linux编译和链接
Linux系统中最常用的编译器是g++。
后续的课程都是在Linux的Ubuntu上进行的。
3.Windows命令行编译器
4.Windows编译器
5.Macintosh上的C++(苹果系统)
第2章 开始学习C++
2.1 编辑/编译/运行第一个c++程序 + 注释
2.1.1 第一个c++程序
(代码见home/reus/Documents/C++_Primer_Plus/2#/1.cpp)
①用nano编辑1.cpp文件;//nano的使用方法见Linux实操篇—二’、文本编辑器nano
②gcc是编译C语言的,g++是用来编译C++的;
③编译生成**.out文件
④执行.out**文件

2.1.2 注释
单行注释+多行注释:

2.1.3 预处理器和iostream文件

2.1.4 头文件名cmath和math.h

2.1.5 名称空间std

2.2 初识运算符重载(<<) + 变量声明和赋值
2.2.1 初识运算符重载
(代码见home/reus/Documents/C++_Primer_Plus/2#/1.cpp)
P18:


2.2.2 变量声明+赋值
P22:

案例:

代码:

2.3 输入指令cin + 类简介
2.3.1 cin
(代码见home/reus/Documents/C++_Primer_Plus/2#/2.cpp)
案例:

注意:1.cpp和2.cpp编译后的文件都是a.out文件,所以如果要执行1.cpp的内容,就要重新对1.cpp进行编译。
所以要养成习惯:在执行.out文件之前,先对.cpp文件进行编译。

文件2.cpp代码:

2.3.2 使用cout拼接

2.3.3 类简介
一个类里有属性(变量)和方法(函数)。
cin和cout就是iostream类的一个对象。
2.4 函数
(代码见home/reus/Documents/C++_Primer_Plus/2#/3.cpp)
C++程序应当为程序中使用的每个函数提供函数原型:
如果是自定义的函数,就应该在main函数之前声明自定义的函数名称(见2.4.2);
如果是库函数,就应该在main函数之前包含对应的头文件(例如:要使用sqrt()函数,就要在main函数之前声明头文件cmath)(见2.4.1)。
2.4.1 调用库函数
案例:
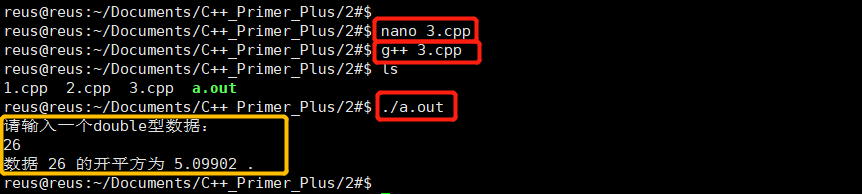
代码:

2.4.2 自定义函数
案例:
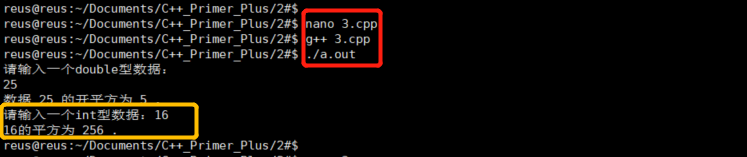
代码:

2.5 总结
本章节比较简单,故没有总结。
2.6 复习题(重新看第11题)
1.C++程序的模块叫什么?
—函数
2.#include的功能是什么?
—包含iostream头文件,将头文件内容添加到源代码中
3.using namespace std;的功能是什么?
—using是预编译器指令,使用std命名空间
4.输出“hello,Linux。”并换行
—cout << “Hello world” << endl;
5.创建名为cheeses的整型变量
—int cheeses;
6.将值32赋给变量cheeses
—cheeses = 32;
7.将从键盘输入的值读入变量cheeses中
—cin >> cheeses;
8.(cout拼接)输出一个整型变量和一个字符串,并换行
—cout << “We have " << cheeses << " varities of cheese,” << endl;
9.C++中函数原型主要包含三方面的内容:函数名、参数列表、返回值
①int froop(double t); ②void rattle(int n); ③int prunt(void);
1)函数名叫froop,带有一个参数t,参数类型是double类型,并且函数返回一个整型值
2)函数名叫rattle,带有一个参数n,参数类型是int类型,该函数无返回值
3)函数名叫prune,函数无参数,函数返回一个整型值
10.什么情况下可以不用谢return?
—当函数没有返回值时,void rattle(int n)
11.假如main函数中包含以下代码:cout << “Please enter your PIN:”; 编译器指出cout是一个未知标识符,原因可能是什么?并写出三种修复这种问题的方法。
原因:没有使用std名称空间
修复方法:
1)using namespace std;//using编译指令
2)using std::cout;//using声明
3)std::cout
2.7 编程练习
(代码见home/reus/Documents/C++_Primer_Plus/2#/4.cpp)

第3章 处理数据
3.1 简单变量
3.1.1 变量名命名规则

3.1.2 整型char、short、int、long、long long

对于计算机而言,可表示的整数变量并不是无限大,而是有范围的。

补充:位bit与字节byte
位(bit):计算机内存的基本单位,0表示关,1表示开。
字节(byte):1B=8bit,1KB=1024B,1MB=1024KB,1GB=1024MB
3.1.3 运算符sizeof() + 头文件climits
(代码见home/reus/Documents/C++_Primer_Plus/3#/1.cpp)
sizeof()
sizeof()返回字节数,括号里可以是类型名,也可以是变量名。

头文件climits
头文件climits定义了符号常量来表示类型的限制。


案例:

初始化(C语言和C++)

C++11初始化方式(不推荐)

3.1.4 无符号类型unsigned + 预处理语句#define(类似宏定义)
只有当数值不会为负时才可以使用无符号类型,如人口、粒数等。
注意:只写一个unsigned就默认表示unsigned int。

案例①:short 和 unsigned short
(代码见home/reus/Documents/C++_Primer_Plus/3#/2.cpp)
unsigned short:0~65535,0-1应该等于65535
short:-32768~32767,32767+1应该等于-32768
用Visual C++ 6.0 和 VS2019编译,结果就是对的,但在Linux上编译,结果却是下面的样子:


结论:short类型有点特殊,(具体解释见**3.4.4 类型转换—③表达式中的转换—整型提升)
再在Linux上测试下int类型试一下(案例②)
案例②:int 和 unsigned int
(代码见home/reus/Documents/C++_Primer_Plus/3#/3.cpp)
unsigned int:0 ~ 4294967295, 0-1应该等于4294967295
int:-2147483648 ~ 2147483647, 2147483647+1应该等于-2147483648

这个结果就对了,所以说short类型比较特殊。
3.1.5 数据类型选择


3.1.6 不同的进制数(二进制、八进制、十六进制)
(代码见home/reus/Documents/C++_Primer_Plus/3#/4.cpp)
不管值是10、012还是0xA,最终都以二进制的形式存储在计算机中。
用cout输入不同进制(默认输出十进制)

代码:
#include<iostream>
#include<bitset>
using namespace std;
int main(){
int m = 26;
cout << dec << "26的十进制数是:" << m << endl;
cout << hex << "26的十六进制数是:" << m << endl;
cout << oct << "26的八进制数是:" << m << endl;
cout << "26的二进制数是:" << bitset<sizeof(int) * 2>(m) << endl;
return 0;
}
3.1.7 C++如何确定常量的类型
后缀是l或L:long常量
后缀是u或U:unsigned int常量
后缀是ul或lu或LU或UL:unsigned long常量

3.1.8 char类型—C++转义字符列表
(代码见home/reus/Documents/C++_Primer_Plus/3#/5.cpp)
C++转义序列的编码

成员函数cout.put()

三种实现换行的代码

signed char 和 unsigned char
char用作数值类型:
unsigned char:0~255
signed char:-128~127
char用作字符类型:有无符号都行。

综合案例:
char c = ‘a’;//char用作字符类型
signed char d = -80;//char用作char数值类型
unsigned char e = 200;//char用作unsigned char数值类型

当d和e的范围超出界限时,输出就会出错:

3.1.9 bool类型
bool flag = true;//真
flag = false;//假
bool flag1 = 10;//真
flag1 = -2;//假
3.2 const限定符—定义符号常量
用const定义符号常量,比#define要好;
用const创建符号常量时要同时进行初始化,const int m = 10; 这样m就不能再变了。

3.3 浮点数
3.3.1 书写方式
第一种是常用的标准小数点表示法;

第二种是E表示法:

3.3.2 浮点数类型—float 和 double
C++对于**有效位数(即精确度)**的要求是:
float至少32位;
double至少48位,且不少于float;
long double至少和double一样多。
通常,float为32位(4字节),double为64位(8字节)。
float的精度比double低,系统确保float至少有6位有效位,double至少有13位是精确的。
这两段话一个说float的有效位数是32位,一个又说float至少有6位有效位,这是怎么回事呢?
答:两种说法都没错,第一段的32位是指二进制的位数,第二段的6位是指十进制的位数。
| float | double |
|---|
| 精确度(十进制) | 至少6位 | 至少13位 |
| 精确度(二进制) | 至少32位 | 至少64位 |
| | |
| 具体的解释见3.3’ 浮点数的存储 + 浮点数为什么不精确 | | |
3.3.3 浮点常量

3.3.4 浮点数的优缺点
(代码见home/reus/Documents/C++_Primer_Plus/2#/6.cpp)
优点:①可以表示整数之间的值;②可以表示的范围更大。
缺点:运算速度慢,并且在运算过程中精度会降低(更多案例见3.4.1中的案例)。
案例:

问题在于:2.34e16是一个小数点左边有16位的数字,已经超过了float的精度(一般是6位),所以在第16位加个1对于变量a来说没有任何影响,所以b-a的结果是0。
3.3’ 浮点数的存储 + 浮点数为什么不精确
问题①:浮点数在系统中是如何存储的?
int型数字5存在系统中就是0101;
那么float数字8.25存在系统中是如何存储的呢?
先将float数以二进制的科学记数法形式表示出来:1.00001 * 2³
然后将其对应到 float的IEEE标准中。
float的IEEE标准:

| 转换过程 | 各部分的名称 | float数8.25 |
|---|
| 二 | 整数部分(十进制) | 8 |
| 进 | 整数部分(二进制) | 1000 |
| 制 | 小数部分(十进制) | 0.25 |
| 科学 | 小数部分的计算过程 | 0.25 * 2=0.5 取整数部分0;
0.5 * 2=1.0 取整数部分1 |
| 计数 | 小数部分(二进制) | 01 |
| 法 | 二进制表示 | 1000.01 |
| 二进制科学记数法表示 | 1.00001 * 2³,其中指数是3,
尾数(小数)部分的前几位是00001 |
| | |
| IE | 符号位(1位) | 0(0表示正数,1表示负数) |
| EE | 指数位(8位) | 127+指数3=130,130的二进制位10000010 |
| 标 | 尾数部分/小数部分(23位) | 00001后面全是0,一共23位 |
| 准 | 存储在系统中的内容为 | 0 10000010 00001000000000000000000 |
| | |
| 问1:指数位为什么是127? | | |
| 答:指数位一共是8位,范围是0~255,其中0 ~126表示负次幂,127 ~255表示正次幂,8.25的指数是3,所以用127+3=130,再算出130的二进制数:10000010。 | | |
| 问2:为什么只有尾数部分,而没有整数部分? | | |
| 答:因为用二进制的科学计数法表示的整数部分都是1,所以就没有存储了。 | | |
 | | |
| 小工具: | | |
 | | |
问题②:float的精度为什么比不上double?
先来解决3.3.2 浮点数类型—float 和 double的问题,为什么一个说float的有效位数是32位,一个又说float至少有6位有效位?
答:两种说法都没错,第一段的32位是指二进制的位数,第二段的6位是指十进制的位数。
| float | double |
|---|
| 精确度(十进制) | 至少6位 | 至少13位 |
| 精确度(二进制) | 至少32位 | 至少64位 |
| float的这个6位和32位怎么能对应上呢? | | |
| 答:float的32位中有23位是尾数部分(小数部分),再加整数部分的那个1,一共是24位,每4位二进制数对应1位十进制数,所以24/4=6,这样就对应上了。 | | |
double的IEEE标准:

同理,double的这个13位和64位怎么能对应上呢?
答:double的64位中有52位是尾数部分(小数部分),再加整数部分的那个1,一共是53位,每4位二进制数对应1位十进制数,所以53/4≈13,这样就对应上了。
综上所述,就能解释为什么float的精度比不上double了,因为float的小数部分是23位,而double的小数部分是52位。
问题③:浮点数为什么不精确?
再来一个例子:
| 转换过程 | 各部分的名称 | float数11.17 |
|---|
| 二 | 整数部分(十进制) | 11 |
| 进 | 整数部分(二进制) | 1011 |
| 制 | 小数部分(十进制) | 0.17 |
| 科学 | 小数部分的计算过程 | 0.17 * 2=0.34 取整数部分0
0.34 * 2=0.68 取整数部分1
0.68 * 2=1.36 取整数部分1
0.36 * 2=0.72 取整数部分0
0.72 * 2=1.44 取整数部分1
0.44 * 2=0.88 取整数部分0
0.88 * 2=1.76 取整数部分1
0.76 * 2=1.52 取整数部分1
0.52 * 2=1.04 取整数部分1
0.04 * 2=0.08 取整数部分0
0.08 * 2=0.16 取整数部分0
0.16 * 2=0.32 取整数部分0
0.32 * 2=0.64 取整数部分0
…(无穷尽) |
| IEEE标准中float的小数部分是23位,double的小数部分是52位,而上表中小数部分的计算是无穷尽的,所以这个23位和52位根本无法记录这么多位,所以虽说double的精度很高,但对于计算机来说无法准确的表达出11.17这个小数点后只有两位的浮点数,这样说来计算机中的float型数11.17就更加不准确了。 | | |
综上所述,计算机中存储的浮点数都是近似值,只能说double比float更接近真实值。
更多的案例:
| 转换过程 | 各部分的名称 | float数26.0 | float数0.75 | float数-2.5 |
|---|
| 二 | 整数部分(十进制) | 26 | 0 | 2 |
| 进 | 整数部分(二进制) | 11010 | 0 | 10 |
| 制 | 小数部分(十进制) | 0.0 | 0.75 | 0.5 |
| 科学 | 小数部分的计算过程 | 0.0 * 2=0.0 取整数部分0;
0.0 * 2=0.0 取整数部分0 | 0.75 * 2=1.5 取整数部分1;
0.5 * 2=1.0 取整数部分1 | 0.5 * 2=1.0 取整数部分1 |
| 计数 | 小数部分(二进制) | 0000 | 11 | 1 |
| 法 | 二进制表示 | 11010.00 | 0.11 | 10.1 |
| 二进制科学记数法表示 | 1.1010 * 2的四次方,其中指数是4,
尾数(小数)部分的前几位是101000 | 1.1 * 2的-1次方,其中指数是 -1,
尾数(小数)部分的前几位是1 | 1.01 * 2的1次方,其中指数是 1,
尾数(小数)部分的前几位是01 |
| | | | |
| IE | 符号位(1位) | 0(0表示正数,1表示负数) | 0 | 1 |
| EE | 指数位(8位) | 127+指数4=131,131的二进制为10000011 | 127-1=126,126的二进制数是01111110 | 127+1=128,128的二进制数是10000000 |
| 标 | 尾数部分/小数部分(23位) | 101000后面全是0,一共23位 | 100后面全是0,共23位 | 01000后面全是0,一共23位 |
| 准 | 存储在系统中的内容为 | 0 10000011 10100000000000000000000 | 0 01111110 10000000000000000000000 | 1 10000000 01000000000000000000000 |
| | | | |
3.4 C++算术运算符 + - * / %
3.4.1 案例 + 运算优先级和结合性
(代码见home/reus/Documents/C++_Primer_Plus/2#/7.cpp)

案例解释①:ostream类的方法setf()
cout.setf(ios_base::fixed,ios_base::floatfield);
通常cout会删除结尾的零,例如将float数33.250000显示为33.25,为了能更好地了解精度,就调用了ostream类的一个方法setf(),它可以防止程序自动把交大的制切换为E表示法,并使程序显示到小数点后6位。
(补充:如果编译器不接受setf()中的ios_base,就用ios)

案例解释②:和为什么是61.419998而不是61.42
因为float类型的有效位数是6位,6位之后就不准确了,这就是3.3.4 浮点数的优缺点中提到的在运算过程中,浮点数的精确度是在降低的。

(注意:如果用double类型,结果就是61.420000)

运算优先级和结合性
优先级:*/高于±
结合性:从左向右
3.4.2 除法分支 + 运算符重载简介
除法分支

(代码见home/reus/Documents/C++_Primer_Plus/2#/8.cpp)

运算符重载
使用相同的符号进行多种操作叫做运算符重载(operator overloading)。
C++有一些内置的重载示例(比如下图中的除法运算符),C++还允许扩展运算符重载,以便能够用于用户自定义的数据类型(类)。

3.4.3 求模运算符
必须是两个整数才可以进行求模运算。
10 / 3 = 3 //除法运算
10 % 3 = 1 //取模运算
3.4.4 类型转换
①初始化和赋值进行的转换:
short-->long
int-->float
float-->double
double-->float
float-->int
long-->short
(代码见home/reus/Documents/C++_Primer_Plus/2#/9.cpp)

解释:
将3.0赋值给变量m;
将3.14的小数部分直接丢弃,把3赋给变量l(C语言初始化方式);
将2.56的小数部分直接丢弃,把2赋给变量n(这种初始化方式是C++所特有的,具体见3.1.3–初始化(C语言和C++))
②以{ }方式初始化时进行的转换(C++11)(这种赋值方式不推荐–3.1.3)

例子:

说明:上面的第五个例子
x = 31325;char c5 = x;
编译没问题,因为对系统而言,这个例子符合赋值操作的语法,所以可以通过编译,但具体赋值之后会出现什么结果就不清楚了,然而上面第1个和第4个例子直接就是错误的代码,编译都过不了。
③表达式中的转换
当同一个表达式中包含两种不同的算术类型时,C++将执行两种自动变换:一种是类型在出现时便会自动变换(见I.整型提升);另一种是和其他类型同时出现在表达式中将被转换(见II.被动转换)。
I.整型提升
这样里有一个新的概念:整型提升(integral promotion)。
在计算表达式时,C++将bool、char、unsigned char、signed char和short值转换为int,这些转换被称为整型提升。
比如下图例子中的line3,当执行line3的语句时,C++程序取得chickens和ducks的值,将他们转换为int,然后把计算的结果转换成short类型。
(通常将int类型作为计算的类型,就意味着可能在使用这种类型时,计算机的计算速度最快。)

补充:
这下就可以理解为什么3.1.4–案例①中为什么(m+1=32768;n-1=-1)了,因为一旦涉及计算,系统就会把m转换成int型。
II.被动转换
当不同类型进行算术运算时,也会进行一些转换,都是将级别低的转换成级别高的。
级别从高到低:
long double > double > float > int ;
有符号整型:long long > long > int > short > signed char ;
无符号整型和有符号整型相同;
类型char、signed char、unsigned char的级别相同;
类型bool的级别最低。

④参数传递时的转换
这个是在后面的函数会用到。
⑤强制类型转换
三种方式:
C语言:(typeName) value
C++:typeName (value)
C++:static_cast< typeName>(value)
C语言:(typeName) value 和 C++:typeName (value)

C++:static_cast(value):

(代码见home/reus/Documents/C++_Primer_Plus/2#/10.cpp)

书上还有一个案例:
要注意区分是先计算再进行强制类型转换,还是先强制类型转换然后才计算。

书上的解释:

3.4.5 C++11中的auto声明

3.5 总结
C++的基本类型:整型(3.1)、浮点型(3.3);
算术运算:加、减、乘、除和求模(取余/取模)(3.4)

3.6 复习题(重新看第2( c)、6、7、9、10(e)题)
(第6、9题的代码见home/reus/Documents/C++_Primer_Plus/2#/11.cpp)
1.为什么C++有多种整型?
答:int, short, long, long long, unsigned char , signed char
根据数据运算的需要选择合适的数据类型和应用进行匹配
2.声明与下述描述相符的变量。
a.short整数,值为80
b.unsigned int数,值为42110
c.值为3000000000的整数
答:
a)short a = 80;
b)unsigned int b = 42110;
c)int的最大值≈2*10的9次方,所以要用unsigned int或者long或者long long:
unsigned int c = 3000000000; long c = 3000000000; long long c = 3000000000;
3.C++提供了什么措施来防止超出整型的范围?
答:C++语言没有提供自动防止超出整数类型范围的功能,需要程序员自己预估数据大小并选择合适的数据类型,每种数据类型的宽度,C++并没有做规定,具体的值由开发平台和编译器决定。
4.33L与33之间有什么区别?
答:默认C++整数常量在不超出int类型范围的应用情况下,默认优先使用int类型
33:int类型
33L:以long类型来存储整数常量
5.下面两条C++语句是否等价?
char grade = 65; 和 char grade = ‘A’;
答:在基于ASCII的平台下,两者是等价的,但是char grade = 65; 先将65存储为int类型,然后再类型转换,将int转换为char存储在grade。
6.如何使用C++来找出编码88表示的字符?指出至少两种方法。
答:
1)初始化方式:
char ch = 88; cout << ch << endl;
2)强制类型转换方式:
cout << (char)88 << endl; 或者
cout << char(88) << endl; 或者
static_cast(88)

7.将long值赋给float变量会导致舍入误差,将long值赋给double变量呢?将long long值赋给double变量呢?
答:
| float | double |
|---|
| 精确度(十进制) | 至少6位 | 至少13位 |
| 精确度(二进制) | 至少32位 | 至少64位 |
float型是4字节,尾数部分是23位;double型是8字节,尾数部分是52位。 (有效位数是尾数部分的位数???)
字节少的赋给字节多的不会出现舍入误差,反之会出现舍入误差。
不同的平台和编译器对应的long和long long类型的大小是不同的:
如果long长度为4字节/32位,则存放在double类型(52位)中不会出现舍入误差;
如果long long类型为8字节/64位,则存放在double类型(52位)中会出现舍入误差。

8.下列C++表达式的结果分别是多少?
答:
a) 89+2 = 74
b) 63/4 = 4
c) 3/46 = 0
d) 6.03/4 = 4.5
e) 15%4 = 3
9.假设 x1 和 x2 是两个double变量,
(1)您要将它们作为整数相加,再将结果赋给一个整型变量。请编写一条完成这项任务的C++语句。
(2)如果要将他们作为double值相加并转换为int呢?
答:考察强制类型转换;
(1)先强制类型转换,再相加:
int sum = (int)x1 + (int)x2; 或者 int sum = int(x1) + int(x2);
(2)先相加再强制类型转换:
int sum = (int)(x1 + x2); 或者 int sum = int(x1+x2);
int sum = x1 + x2;这个应该也行吧???—可以的

10.下面每条语句声明的变量都是什么类型?

答:
a)cars—>int
b)iou --> float
c)level --> char
d)crat —> char32_t
e)fract --> double???8.25f为float类型,2.5位double类型,所以fract变量为double类型。
3.7 编程练习
都是关于单位转换的题目,第三题注意一下;
用int/int的时候如果把结果赋给float型,要在int型数前加个(float)进行强制类型转换,否则结果会出错。

第4章 复合类型
见链接
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)