因最近学习了scala重温spark,本篇主要是spark rdd的基础编程题
原题目地址: 题目地址
数据准备
本题所需的数据 data.txt
数据结构如下依次是:班级 姓名 年龄 性别 科目 成绩
12 宋江 25 男 chinese 50
12 宋江 25 男 math 60
12 宋江 25 男 english 70
12 吴用 20 男 chinese 50
12 吴用 20 男 math 50
12 吴用 20 男 english 50
12 杨春 19 女 chinese 70
12 杨春 19 女 math 70
12 杨春 19 女 english 70
13 李逵 25 男 chinese 60
13 李逵 25 男 math 60
13 李逵 25 男 english 70
13 林冲 20 男 chinese 50
13 林冲 20 男 math 60
13 林冲 20 男 english 50
13 王英 19 女 chinese 70
13 王英 19 女 math 80
13 王英 19 女 english 70
题目如下:
1. 读取文件的数据test.txt
2. 一共有多少个小于20岁的人参加考试?
3. 一共有多少个等于20岁的人参加考试?
4. 一共有多少个大于20岁的人参加考试?
5. 一共有多个男生参加考试?
6. 一共有多少个女生参加考试?
7. 12班有多少人参加考试?
8. 13班有多少人参加考试?
9. 语文科目的平均成绩是多少?
10. 数学科目的平均成绩是多少?
11. 英语科目的平均成绩是多少?
12. 每个人平均成绩是多少?
13. 12班平均成绩是多少?
14. 12班男生平均总成绩是多少?
15. 12班女生平均总成绩是多少?
16. 13班平均成绩是多少?
17. 13班男生平均总成绩是多少?
18. 13班女生平均总成绩是多少?
19. 全校语文成绩最高分是多少?
20. 12班语文成绩最低分是多少?
21. 13班数学最高成绩是多少?
22. 总成绩大于150分的12班的女生有几个?
23. 总成绩大于150分,且数学大于等于70,且年龄大于等于19岁的学生的平均成绩是多少?
代码答案如下:(自测代码,非最优解)
import org.apache.spark.{SparkConf, SparkContext}
object test_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("myapp")
val sc = new SparkContext(conf)
val rdd = sc.textFile("C:/Users/yusyu/Desktop/data.txt")
val a = rdd.map(x => x.split(" ")).filter(x => x(2).toInt < 20).groupBy(x => x(1)).count()
println("小于20岁的人数:" + a)
val b = rdd.map(x => x.split(" ")).filter(x => x(2).toInt == 20).groupBy(x => x(1)).count()
println("等于20岁的人数:" + b)
val c = rdd.map(x => x.split(" ")).filter(x => x(2).toInt > 20).groupBy(x => x(1)).count()
println("大于20岁的人数:" + c)
val d = rdd.map(x => x.split(" ")).filter(x => x(3).toString == "男").groupBy(x => x(1)).count()
println("参加考试男生的人数:" + d)
val e = rdd.map(x => x.split(" ")).filter(x => x(3).toString == "女").groupBy(x => x(1)).count()
println("参加考试女生的人数:" + e)
val f = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12).groupBy(x => x(1)).count()
println("12班参加考试的人数:" + f)
val g = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13).groupBy(x => x(1)).count()
println("13班参加考试的人数:" + g)
val h = rdd.map(x => x.split(" ")).filter(x => x(4) == "chinese").map(x => (x(4), (x(5).toInt, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._2._1 / x._2._2)).collect()
println("语文的平均成绩是:" + h.mkString(""))
val i = rdd.map(x => x.split(" ")).filter(x => x(4) == "math").map(x => (x(4), (x(5).toInt, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._2._1 / x._2._2)).collect()
println("数学的平均成绩是:" + i.mkString(""))
val j = rdd.map(x => x.split(" ")).filter(x => x(4) == "english").map(x => (x(4), (x(5).toInt, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._2._1 / x._2._2)).collect()
println("英语的平均成绩是:" + j.mkString(""))
val k = rdd.map(x => x.split(" ")).map(x => (x(1), (x(5).toInt, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("每个人的平均成绩是:" + k.mkString(" "))
val l = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12).map(x => (x(4), ((x(5).toInt, 1)))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("12班的平均成绩是: " + l.mkString(" "))
val m = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12 && x(3) == "男").map(x => (x(1), ((x(5).toInt), 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("12班的男生平均总成绩是: " + m.mkString(" "))
val n = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13 && x(3) == "女").map(x => (x(1), ((x(5).toInt), 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("12班的女生平均总成绩是: " + n.mkString(" "))
val o = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13).map(x => (x(4), ((x(5).toInt, 1)))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("13班的平均成绩是: " + o.mkString(" "))
val p = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13 && x(3) == "男").map(x => (x(1), ((x(5).toInt), 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("13班的男生平均总成绩是: " + p.mkString(" "))
val q = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13 && x(3) == "女").map(x => (x(1), ((x(5).toInt), 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("13班的女生平均总成绩是: " + q.mkString(" "))
val r = rdd.map(x => x.split(" ")).filter(x => x(4) == "chinese").map(x => (x(1), x(5).toInt)).sortBy(_._2, false).take(1)
println("全校语文成绩最高分是: " + r.mkString(" "))
val s = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12 && x(4) == "chinese").map(x => (x(1), x(5).toInt)).sortBy(_._2).take(1)
println("12班语文成绩最低分是: " + s.mkString(" "))
val t = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13 && x(4) == "math").map(x => (x(1), x(5).toInt)).sortBy(_._2, false).take(1)
println("13班数学成绩最高分是: " + t.mkString(" "))
val u = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12).map(x => (x(1), (x(5).toInt))).reduceByKey((x, y) => (x + y)).filter(_._2 > 150).collect()
println("12班总成绩大于150的女生有: " + u.mkString(" "))
val v = rdd.map(x => x.split(" ")).map(x => (x(1), x(5).toInt)).reduceByKey((x, y) => (x + y)).filter(x => x._2 > 150)
val w = rdd.map(x => x.split(" ")).filter(x => x(2).toInt > 18 && x(4) == "math" && x(5).toInt > 69).map(x => (x(1), 3))
val x = v.join(w).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("总成绩大于150,且数学大于等于70,且年龄大于等于19岁的学生的平均成绩是:" + x.mkString(" "))
sc.stop()
}
}
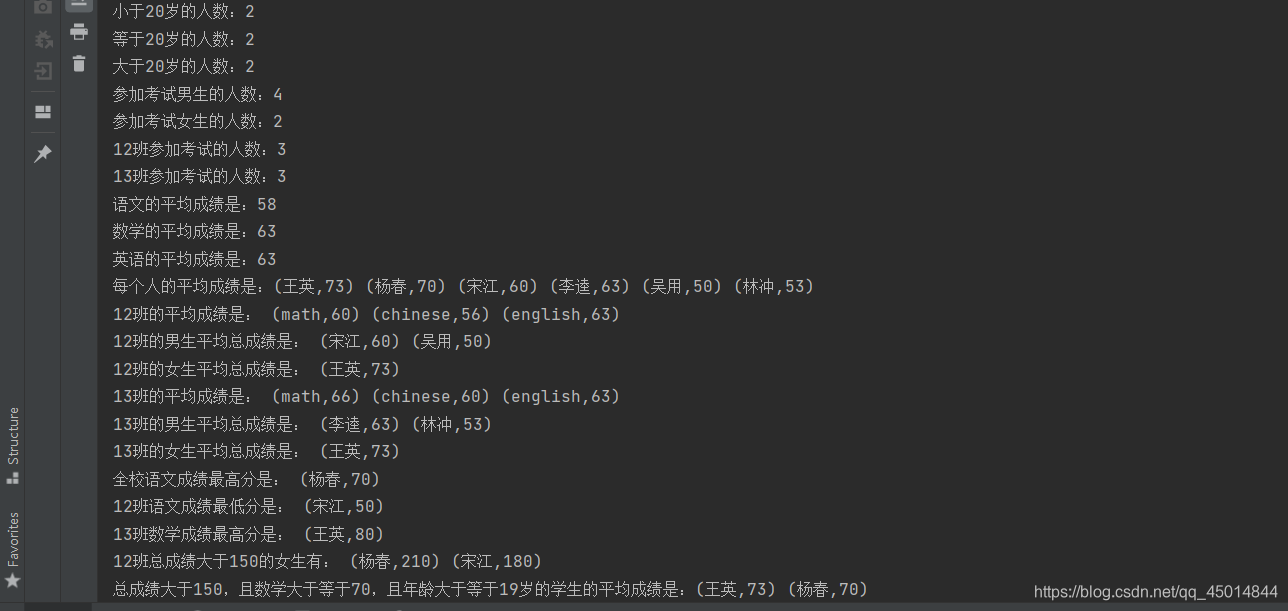
部分结果如下:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)