因最近学习了scala重温spark,本篇主要是spark sql与rdd的基础编程题
第一部分SparkRDD:
原题目地址: 题目地址
数据准备
本题所需的数据 data.txt
数据结构如下依次是:班级 姓名 年龄 性别 科目 成绩
12 宋江 25 男 chinese 50
12 宋江 25 男 math 60
12 宋江 25 男 english 70
12 吴用 20 男 chinese 50
12 吴用 20 男 math 50
12 吴用 20 男 english 50
12 杨春 19 女 chinese 70
12 杨春 19 女 math 70
12 杨春 19 女 english 70
13 李逵 25 男 chinese 60
13 李逵 25 男 math 60
13 李逵 25 男 english 70
13 林冲 20 男 chinese 50
13 林冲 20 男 math 60
13 林冲 20 男 english 50
13 王英 19 女 chinese 70
13 王英 19 女 math 80
13 王英 19 女 english 70
题目如下:
1. 读取文件的数据test.txt
2. 一共有多少个小于20岁的人参加考试?
3. 一共有多少个等于20岁的人参加考试?
4. 一共有多少个大于20岁的人参加考试?
5. 一共有多个男生参加考试?
6. 一共有多少个女生参加考试?
7. 12班有多少人参加考试?
8. 13班有多少人参加考试?
9. 语文科目的平均成绩是多少?
10. 数学科目的平均成绩是多少?
11. 英语科目的平均成绩是多少?
12. 每个人平均成绩是多少?
13. 12班平均成绩是多少?
14. 12班男生平均总成绩是多少?
15. 12班女生平均总成绩是多少?
16. 13班平均成绩是多少?
17. 13班男生平均总成绩是多少?
18. 13班女生平均总成绩是多少?
19. 全校语文成绩最高分是多少?
20. 12班语文成绩最低分是多少?
21. 13班数学最高成绩是多少?
22. 总成绩大于150分的12班的女生有几个?
23. 总成绩大于150分,且数学大于等于70,且年龄大于等于19岁的学生的平均成绩是多少?
代码答案如下:(自测代码,非最优解)
import org.apache.spark.{SparkConf, SparkContext}
object test_2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("myapp")
val sc = new SparkContext(conf)
val rdd = sc.textFile("C:/Users/yusyu/Desktop/data.txt")
val a = rdd.map(x => x.split(" ")).filter(x => x(2).toInt < 20).groupBy(x => x(1)).count()
println("小于20岁的人数:" + a)
val b = rdd.map(x => x.split(" ")).filter(x => x(2).toInt == 20).groupBy(x => x(1)).count()
println("等于20岁的人数:" + b)
val c = rdd.map(x => x.split(" ")).filter(x => x(2).toInt > 20).groupBy(x => x(1)).count()
println("大于20岁的人数:" + c)
val d = rdd.map(x => x.split(" ")).filter(x => x(3).toString == "男").groupBy(x => x(1)).count()
println("参加考试男生的人数:" + d)
val e = rdd.map(x => x.split(" ")).filter(x => x(3).toString == "女").groupBy(x => x(1)).count()
println("参加考试女生的人数:" + e)
val f = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12).groupBy(x => x(1)).count()
println("12班参加考试的人数:" + f)
val g = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13).groupBy(x => x(1)).count()
println("13班参加考试的人数:" + g)
val h = rdd.map(x => x.split(" ")).filter(x => x(4) == "chinese").map(x => (x(4), (x(5).toInt, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._2._1 / x._2._2)).collect()
println("语文的平均成绩是:" + h.mkString(""))
val i = rdd.map(x => x.split(" ")).filter(x => x(4) == "math").map(x => (x(4), (x(5).toInt, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._2._1 / x._2._2)).collect()
println("数学的平均成绩是:" + i.mkString(""))
val j = rdd.map(x => x.split(" ")).filter(x => x(4) == "english").map(x => (x(4), (x(5).toInt, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._2._1 / x._2._2)).collect()
println("英语的平均成绩是:" + j.mkString(""))
val k = rdd.map(x => x.split(" ")).map(x => (x(1), (x(5).toInt, 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("每个人的平均成绩是:" + k.mkString(" "))
val l = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12).map(x => (x(4), ((x(5).toInt, 1)))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("12班的平均成绩是: " + l.mkString(" "))
val m = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12 && x(3) == "男").map(x => (x(1), ((x(5).toInt), 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("12班的男生平均总成绩是: " + m.mkString(" "))
val n = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13 && x(3) == "女").map(x => (x(1), ((x(5).toInt), 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("12班的女生平均总成绩是: " + n.mkString(" "))
val o = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13).map(x => (x(4), ((x(5).toInt, 1)))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("13班的平均成绩是: " + o.mkString(" "))
val p = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13 && x(3) == "男").map(x => (x(1), ((x(5).toInt), 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("13班的男生平均总成绩是: " + p.mkString(" "))
val q = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13 && x(3) == "女").map(x => (x(1), ((x(5).toInt), 1))).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("13班的女生平均总成绩是: " + q.mkString(" "))
val r = rdd.map(x => x.split(" ")).filter(x => x(4) == "chinese").map(x => (x(1), x(5).toInt)).sortBy(_._2, false).take(1)
println("全校语文成绩最高分是: " + r.mkString(" "))
val s = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12 && x(4) == "chinese").map(x => (x(1), x(5).toInt)).sortBy(_._2).take(1)
println("12班语文成绩最低分是: " + s.mkString(" "))
val t = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 13 && x(4) == "math").map(x => (x(1), x(5).toInt)).sortBy(_._2, false).take(1)
println("13班数学成绩最高分是: " + t.mkString(" "))
val u = rdd.map(x => x.split(" ")).filter(x => x(0).toInt == 12).map(x => (x(1), (x(5).toInt))).reduceByKey((x, y) => (x + y)).filter(_._2 > 150).collect()
println("12班总成绩大于150的女生有: " + u.mkString(" "))
val v = rdd.map(x => x.split(" ")).map(x => (x(1), x(5).toInt)).reduceByKey((x, y) => (x + y)).filter(x => x._2 > 150)
val w = rdd.map(x => x.split(" ")).filter(x => x(2).toInt > 18 && x(4) == "math" && x(5).toInt > 69).map(x => (x(1), 3))
val x = v.join(w).map(x => (x._1, x._2._1 / x._2._2)).collect()
println("总成绩大于150,且数学大于等于70,且年龄大于等于19岁的学生的平均成绩是:" + x.mkString(" "))
sc.stop()
}
}
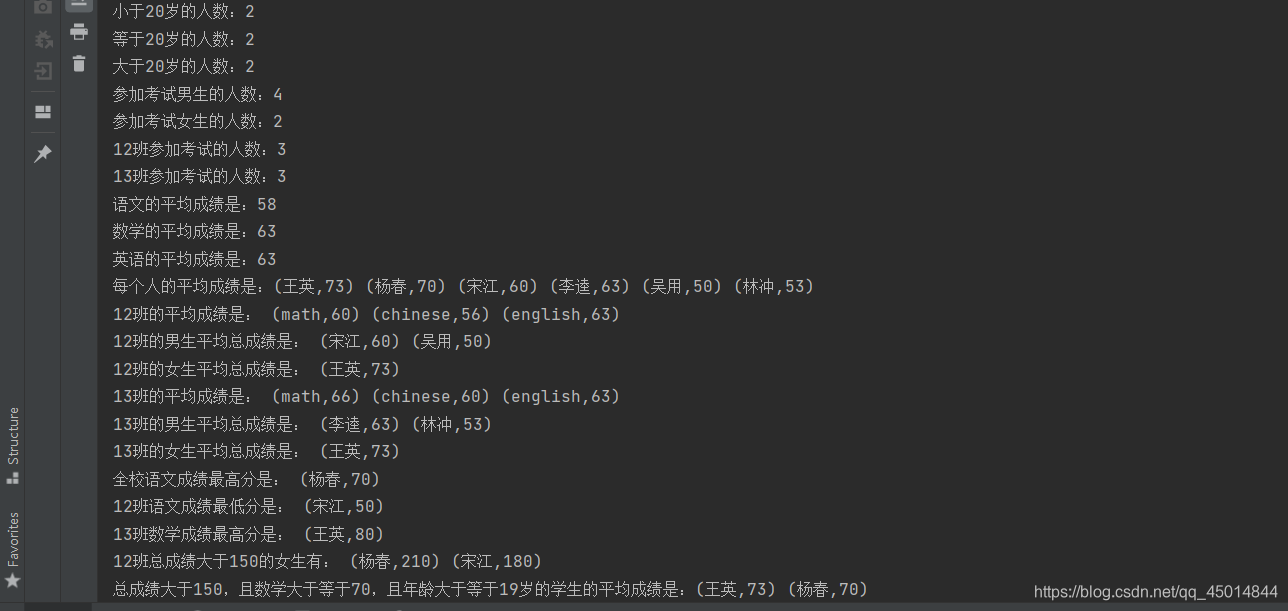
部分结果如下:
第二部分SparkSQL:
原题目地址: 题目地址
数据准备
本次所需的数据
student.txt
字段说明
学号 学生姓名 学生性别 学生出生年月 学生所在班级
108 丘东 男 1977-09-01 95033
105 匡明 男 1975-10-02 95031
107 王丽 女 1976-01-23 95033
101 李军 男 1976-02-20 95033
109 王芳 女 1975-02-10 95031
103 陆君 男 1974-06-03 95031
course.txt
字段说明
课程号 课程名称 教工编号
3-105 计算机导论 825
3-245 操作系统 804
6-166 数字电路 856
9-888 高等数学 831
score.txt
字段说明
学号 课程号 成绩
103 3-245 86
105 3-245 75
109 3-245 68
103 3-105 92
105 3-105 88
109 3-105 76
101 3-105 64
107 3-105 91
108 3-105 78
101 6-166 85
107 6-166 79
108 6-166 81
teacher.txt
字段说明
教工编号 教工姓名 教工性别 教工出生年月 职称 教工所在部门
804 李诚 男 1958-12-02 副教授 计算机系
856 张旭 男 1969-03-12 讲师 电子工程系
825 王萍 女 1972-05-05 助教 计算机系
831 刘冰 女 1977-08-14 助教 电子工程系
题目如下:
1.查询Student表中“95031”班或性别为“女”的同学记录。
2.以Class降序,升序查询Student表的所有记录。
3.以Cno升序、Degree降序查询Score表的所有记录。
4.查询“95031”班的学生。
5.查询Score表中的最高分的学生学号和课程号。(子查询或者排序)
6.查询每门课的平均成绩。
7.查询Score表中至少有5名学生选修的并以3开头的课程的平均分数。
8.查询分数大于70,小于90的Sno列。
9.查询所有学生的Sname、Cno和Degree列。
10.查询所有学生的Sno、Cname和Degree列。
11.查询所有学生的Sname、Cname和Degree列。
12.查询“95033”班学生的平均分。
13.查询所有选修“计算机导论”课程的“女”同学的成绩表。
14.查询选修“3-105”课程的成绩高于“109”号同学成绩的所有同学的记录。
15.查询score中选学多门课程的同学中分数为非最高分成绩的记录。
16.查询成绩高于学号为“109”、课程号为“3-105”的成绩的所有记录。
17.查询和学号为105的同学同年出生的所有学生的Sno、Sname和Sbirthday列。
18.查询“张旭“教师任课的学生成绩
19.查询选修某课程的同学人数多于4人的教师姓名
20.查询95033班和95031班全体学生的记录
21.查询存在有85分以上成绩的课程Cno
22.查询出“计算机系“教师所教课程的成绩表
23.查询“计算机系”与“电子工程系“不同职称的教师的Tname和Prof
24.查询选修编号为“3-105“课程且成绩至少高于选修编号为“3-245”的同学的Cno、Sno和Degree,并按Degree从高到低次序排序
25.查询选修编号为“3-105”且成绩高于选修编号为“3-245”课程的同学的Cno、Sno和Degree
26.查询所有教师和同学的name、sex和birthday
27.查询所有“女”教师和“女”同学的name、sex和birthday.
28.查询成绩比该课程平均成绩低的同学的成绩表
29.查询所有任课教师的Tname和Depart
30.查询所有未讲课的教师的Tname和Depart
31.查询至少有2名男生的班号
32.查询Student表中不姓“王”的同学记录
33.查询Student表中每个学生的姓名和年龄。
34.查询Student表中最大和最小的Sbirthday日期值。(时间格式最大值,最小值)
35.以班号和年龄从大到小的顺序查询Student表中的全部记录。 查询结果排序
36.查询“男”教师及其所上的课程
37.查询最高分同学的Sno、Cno和Degree列
38.查询和“李军”同性别的所有同学的Sname
39.查询和“李军”同性别并同班的同学Sname
40.查询所有选修“计算机导论”课程的“男”同学的成绩表
41.查询Student表中的所有记录的Sname、Ssex和Class列
42.查询教师所有的单位即不重复的Depart列
43.查询Student表的所有记录
44.查询Score表中成绩在60到80之间的所有记录
45.查询Score表中成绩为85,86或88的记录
代码答案如下:(自测代码,非最优解)
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object test_6_sparksql {
case class Student(Sno: String, Sname: String, Ssex: String, Sbirthday: String, Class: String)
case class Course(Cno: String, Cname: String, Tno: String)
case class Score(Sno: String, Cno: String, Degree: String)
case class Teacher(Tno: String, Tname: String, Tsex: String, Tbirthday: String, Prof: String, Depart: String)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("myapp")
val spark = SparkSession.builder().config(conf).getOrCreate()
val sc = spark.sparkContext
val data1 = sc.textFile("C:/Users/yusyu/Desktop/sparksql/student.txt")
val data2 = sc.textFile("C:/Users/yusyu/Desktop/sparksql/course.txt")
val data3 = sc.textFile("C:/Users/yusyu/Desktop/sparksql/score.txt")
val data4 = sc.textFile("C:/Users/yusyu/Desktop/sparksql/teacher.txt")
val student = data1.map(x => {
val str = x.split("\t");
Student(str(0), str(1), str(2), str(3), str(4))
})
val course = data2.map(x => {
val str = x.split("\t");
Course(str(0), str(1), str(2))
})
val score = data3.map(x => {
val str = x.split("\t");
Score(str(0), str(1), str(2))
})
val teacher = data4.map(x => {
val str = x.split("\t");
Teacher(str(0), str(1), str(2), str(3), str(4), str(5))
})
import spark.implicits._
val stuframe = student.toDF()
val couframe = course.toDF()
val scoframe = score.toDF()
val teaframe = teacher.toDF()
stuframe.createOrReplaceTempView("student")
couframe.createOrReplaceTempView("course")
scoframe.createOrReplaceTempView("score")
teaframe.createOrReplaceTempView("teacher")
spark.sql("select * from student where Class='95031' or Ssex='女'").show()
spark.sql("select * from student order by Class desc").show()
spark.sql("select * from score order by Cno,Degree desc").show()
spark.sql("select * from student where Class='95031'").show()
spark.sql("select Sno,Cno from score where Degree = (select MAX(Degree) from score)").show()
spark.sql("select first(course.Cname),avg(Degree) from score left join course on score.Cno=course.Cno group by score.Cno").show()
spark.sql("select first(Cno),avg(Degree) from score where Cno like '3%' group by Cno having count(*)>4").show()
spark.sql("select Sno from score where Degree>70 and Degree<90").show()
spark.sql("select student.Sname,score.Cno,score.Degree from student left join score on student.Sno=score.Sno").show()
spark.sql("select student.Sno,course.Cname,score.Degree from student,score,course where student.Sno=score.Sno and course.Cno=score.Cno").show()
spark.sql("select student.Sname,course.Cname,score.Degree from student,score,course where student.Sno=score.Sno and course.Cno=score.Cno").show()
spark.sql("select avg(score.Degree) from score,student where student.Sno=score.Sno and student.Class='95033'").show()
spark.sql("select student.Sname,course.Cname,score.Degree from score,student,course where student.Sno=score.Sno and course.Cno=score.Cno and course.Cname='计算机导论' and student.Ssex='女'").show()
spark.sql("select * from score where Cno='3-105' and Degree>(select Degree from score where Sno='109' and Cno = '3-105')").show()
spark.sql(
"""
|select * from score a where Sno in
|(select Sno from score group by Sno having count(*)>1)
|and Degree <(select MAX(Degree) from score b where a.Cno=b.Cno)
|""".stripMargin).show()
spark.sql("select * from score where Cno='3-105' and Degree>(select MAX(Degree) from score where Sno='109')").show()
spark.sql("select Sno,Sname,Sbirthday from student where year(Sbirthday) = (select year(Sbirthday) from student where Sno='105')").show()
spark.sql("select course.Cname,score.Degree from course,score,teacher where teacher.Tname='张旭' and teacher.Tno=course.Tno and course.Cno=score.Cno").show()
spark.sql(
"""
|select Tname
|from teacher
|where teacher.Tno=(select Tno
|from course
|where Cno=(select Cno
|from score
|group by Cno
|having count(Cno)>4))
|""".stripMargin).show()
spark.sql("select * from student where Class='95033' or Class='95031'").show()
spark.sql("select Cno from (select * from score where Degree>85) group by Cno").show()
spark.sql("select teacher.Depart,score.Cno,score.Degree from teacher,score,course where teacher.Tno=course.Tno and course.Cno=score.Cno and teacher.Depart='计算机系'").show()
spark.sql("select distinct a.Tname,a.Prof from teacher a,teacher a1 where a.Depart!=a1.Depart and a.Prof not in (select Prof from teacher group by Prof having count(*)>1)").show()
spark.sql(
"""
|select a.Cno,a.Sno,a.Degree
|from score a,score b
|where a.Sno=b.Sno and a.Cno='3-105' and b.Cno='3-245' and a.Degree>b.Degree
|order by a.Degree desc
|""".stripMargin).show()
spark.sql(
"""
|select a.Cno,a.Sno,a.Degree
|from score a,score b
|where a.Sno=b.Sno and a.Cno='3-105' and b.Cno='3-245' and a.Degree>b.Degree
|""".stripMargin).show()
spark.sql(
"""
|select Tname,Tsex,Tbirthday
|from teacher
|union
|select Sname,Ssex,Sbirthday
|from student
|""".stripMargin).show()
spark.sql(
"""
|select Tname,Tsex,Tbirthday
|from teacher
|where Tsex='女'
|union
|select Sname,Ssex,Sbirthday
|from student
|where Ssex='女'
|""".stripMargin).show()
spark.sql(
"""
|select Sno,Cno,Degree
|from score a
|where Degree<(select avg(Degree) from score b where a.Cno=b.Cno)
|""".stripMargin).show()
spark.sql("select distinct teacher.Tname,Depart from teacher,score,course where score.Cno=course.Cno and course.Tno=teacher.Tno").show()
spark.sql(
"""
|select Tname,Depart
|from teacher
|where Tname not in (select distinct teacher.Tname from teacher,score,course where score.Cno=course.Cno and course.Tno=teacher.Tno)
|""".stripMargin).show()
spark.sql("select Class from student group by Class having (select count(*) from student where Ssex='男')>2").show()
spark.sql("select * from student where Sname not in (select Sname from student where Sname like '王%')").show()
spark.sql("select Sname,(year(now())-year(Sbirthday))as age from student").show()
spark.sql("select MAX(Sbirthday),MIN(Sbirthday) from student").show()
spark.sql("select * from student order by Class,Sbirthday").show()
spark.sql("select teacher.Tname,course.Cname from teacher,course where teacher.Tno=course.Tno and teacher.Tsex='男'").show()
spark.sql("select Sno,Cno,Degree from score where Degree=(select MAX(Degree) from score)").show()
spark.sql("select Sname from student where Sname!='李军' and Ssex=(select Ssex from student where Sname='李军')").show()
spark.sql("select Sname from student where Sname!='李军' and Ssex=(select Ssex from student where Sname='李军') and Class=(select Class from student where Sname='李军')").show()
spark.sql("select student.Sname,Degree from course,score,student where score.Cno=course.Cno and course.Cname='计算机导论' and score.Sno=student.Sno and student.Ssex='男'").show()
spark.sql("select Sname,Ssex,Class from student").show()
spark.sql("select distinct Depart from teacher").show()
spark.sql("select * from student").show()
spark.sql("select * from score where Degree between 60 and 80").show()
spark.sql("select * from score where Degree=85 or Degree=86 or Degree=88").show()
spark.close()
}
}
部分结果如下:

题目较多,建议选择题号为10-30的题目进行选择练习
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)