1. Spark 数据分析简介
1.1 Spark 是什么
Spark 是一个用来实现快速而通用的集群计算的平台。
在速度方面,Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是必须在磁盘上进行的复杂计算,Spark 依然比 MapReduce 更加高效。
Spark 所提供的接口非常丰富。除了提供基于 Python、Java、Scala 和 SQL 的简单易用的API 以及内建的丰富的程序库以外,Spark 还能和其他大数据工具密切配合使用。例如,Spark 可以运行在 Hadoop 集群上,访问包括 Cassandra 在内的任意 Hadoop 数据源。
1.2 Spark 软件栈

1.2.1 Spark Core
Spark Core 实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称 RDD)的 API 定义。RDD 表示分布在多个计算节点上可以并行操作的元素集合,是Spark 主要的编程抽象。Spark Core 提供了创建和操作这些集合的多个 API。
1.2.2 Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等。Spark SQL 还支持开发者将 SQL 和传统的 RDD 编程的数据操作方式相结合。
1.2.3 Spark Streaming
Spark Streaming 是 Spark 提供的对实时数据进行流式计算的组件。比如生产环境中的网页服务器日志,或是网络服务中用户提交的状态更新组成的消息队列,都是数据流。
1.2.4 MLlib
Spark 中还包含一个提供常见的机器学习(ML)功能的程序库,叫作 MLlib。MLlib 提供了很多种机器学习算法,包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
1.2.5 GraphX
GraphX 是用来操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算。
1.2.6 集群管理器
就底层而言,Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(clustermanager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度器,叫作独立调度器(standalone)。如果要在没有预装任何集群管理器的机器上安装 Spark,那么 Spark自带的独立调度器可以让你轻松入门;而如果已经有了一个装有 Hadoop YARN 或 Mesos的集群,通过 Spark 对这些集群管理器的支持,你的应用也同样能运行在这些集群上。
2. 初识Spark
在 Java 和 Scala 中,只需要给你的应用添加一个对于 spark-core 工件的 Maven 依赖,便可以进行Spark的开发,新建Maven项目在pom文件中添加:
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.11.8</scala.version>
<spark.version>2.1.0</spark.version>
<hadoop.version>2.6.5</hadoop.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
</plugins>
</pluginManagement>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.1 Scala 版本的单词数统计应用
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object ScalaWordCount {
def main(args: Array[String]): Unit = {
// 创建SparkContext并配置信息
val conf = new SparkConf().setMaster("local").setAppName("WC")
val sc = new SparkContext(conf)
// 指定从哪读取数据并生成RDD
val lines: RDD[String] = sc.textFile("words.txt")
// 将每一行的内容进行切分并压平
val words: RDD[String] = lines.flatMap(_.split(" "))
// 将每个单词和“1”放到一个元组中
val mapped: RDD[(String, Int)] = words.map((_,1))
// 继续聚合
val reduced: RDD[(String, Int)] = mapped.reduceByKey(_+_)
// 排序
val sorted: RDD[(String, Int)] = reduced.sortBy(_._2,false)
// 引发求值并输出
sorted.foreach(println)
// 释放资源
sc.stop()
}
}
2.2 Java 版本的单词数统计应用
public class JavaWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("WC");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("words.txt");
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
JavaPairRDD<String, Integer> mapped = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<>(word,1);
}
});
JavaPairRDD<String, Integer> reduced = mapped.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD<Integer, String> swapd = reduced.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tp2) throws Exception {
return tp2.swap();
}
});
JavaPairRDD<Integer, String> sorted = swapd.sortByKey(false);
JavaPairRDD<String, Integer> result = sorted.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> tp2) throws Exception {
return tp2.swap();
}
});
result.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tp2) throws Exception {
System.out.println(tp2);
}
});
jsc.stop();
}
}
2.3 JavaLambda 版本的单词数统计应用
public class LambdaWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("WC");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("words.txt");
JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairRDD<String, Integer> mapped = words.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> reduced = mapped.reduceByKey((x, y) -> (x + y));
JavaPairRDD<Integer, String> swaped = reduced.mapToPair(tp2 -> tp2.swap());
JavaPairRDD<Integer, String> sorted = swaped.sortByKey(false);
JavaPairRDD<String, Integer> result = sorted.mapToPair(tp2 -> tp2.swap());
result.foreach(tp2 -> System.out.println(tp2));
jsc.stop();
}
}
3. RDD 编程
3.1 RDD 基础
RDD是 Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset),Spark 中的 RDD 就是一个不可变的分布式对象集合。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。RDD 有五大特性:
- RDD 是由一系列的 partition 组成的。
- 函数是作用在每一个 partition(split)上的。
- RDD 之间有一系列的依赖关系。
- 分区器是作用在 K,V 格式的 RDD 上。
- RDD 提供一系列最佳的计算位置。
- 哪里体现 RDD 的弹性(容错)?
- partition 数量,大小没有限制,体现了 RDD 的弹性。
- RDD 之间依赖关系,可以基于上一个 RDD 重新计算出 RDD。
- 哪里体现 RDD 的分布式?
- RDD 是由 Partition 组成,partition 是分布在不同节点上的。
- RDD 提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动数据不移动”的理念。
3.2 Transformations 转换算子
Transformations 类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey 等。Transformations 算子是延迟执行,也叫懒加载执行。
| Transformation 类算子 | 概述 |
|---|
| map | 将一个 RDD 中的每个数据项,通过 map 中的函数映射变为一个新的元素 |
| filter | 过滤操作,满足filter内function函数为true的RDD内所有元素组成一个新的数据集。 |
| flatMap | 先 map 后 flat。与 map 类似,每个输入项可以映射为 0 到多个输出项 |
| sample | 随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样 |
| reduceByKey | 将相同的 Key 根据相应的逻辑进行处理 |
| sortByKey/sortBy | 作用在 K,V 格式的 RDD 上,对 key 进行升序或者降序排序 |
| mapPartitions | 与 map 类似,遍历的单位是每个 partition 上的数据 |
| mapPartitionsWithIndex | 类似于 mapPartitions,除此之外还会携带分区的索引值 |
| union | 合并两个数据集。两个数据集的类型要一致,不去重 |
| intersection | 对于源数据集和其他数据集求交集,并去重,且无序返回 |
| subtract | 取两个数据集的差集 |
| distinct | 返回一个在源数据集去重之后的新数据集,即去重,并局部无序而整体有序返回 |
| groupByKey | 将相同的所有的键值对分组到一个集合序列当中,其顺序是不确定的,若一个键对应值太多,则易导致内存溢出 |
| cogroup | 当调用类型(K,V)和(K,W)的数据上时,返回一个数据集(K,(Iterable,Iterable)) |
| aggregateByKey | 类似reduceByKey,对pairRDD中想用的key值进行聚合操作,使用初始值 |
| join | 加入一个RDD,在一个(k,v)和(k,w)类型的dataSet上调用,返回一个(k,(v,w))的pair dataSet |
| cartesian | 求笛卡尔乘积,该操作不会执行shuffle操作 |
| pipe | 通过一个shell命令来对RDD各分区进行“管道化” |
| coalesce | 重新分区,减少RDD中分区的数量到numPartitions |
| repartition | repartition是coalesce接口中shuffle为true的简易实现,即Reshuffle RDD并随机分区,使各分区数据量尽可能平衡。若分区之后分区数远大于原分区数,则需要shuffle |
3.3 Action 行动算子
Action 类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count 等。Transformations 类算子是延迟执行,Action 类算子是触发执行。一个 application 应用程序中有几个 Action 类算子执行,就有几个 job 运行。
| Action 类算子 | 概述 |
|---|
| count | 返回数据集中的元素数。会在结果计算完成后回收到 Driver 端 |
| take(n) | 返回一个包含数据集前 n 个元素的集合 |
| first | first=take(1),返回数据集中的第一个元素 |
| foreach | 循环遍历数据集中的每个元素,运行相应的逻辑 |
| collect | 将计算结果回收到 Driver 端 |
| foreachPartition | 遍历的数据是每个 partition 的数据 |
| countByKey | 作用到 K,V 格式的 RDD 上,根据 Key 计数相同 Key 的数据集元素 |
| countByValue | 根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数 |
| reduce | 根据聚合逻辑聚合数据集中的每个元素 |
| saveAsTextFile | 将dataSet中元素以文本文件的形式写入本地文件系统或者HDFS等。Spark将对每个元素调用toString方法,将数据元素转换为文本文件中的一行记录 |
3.4 控制算子
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD 持久化,持久化的单位是 partition。cache 和 persist 都是懒执行的。必须有一个 action 类算子触发执行。checkpoint 算子不仅能将 RDD 持久化到磁盘,还能切断 RDD 之间的依赖关系。
| 控制算子 | 概述 |
|---|
| cache | 默认将 RDD 的数据持久化到内存中。cache 是懒执行。 |
| persist | 可以指定持久化的级别。最常用的是 MEMORY_ONLY 和MEMORY_AND_DISK。”_2”表示有副本数 |
| checkpoint | checkpoint 将 RDD 持久化到磁盘,还可以切断 RDD 之间的依赖关系 |
4. 在集群上运行 Spark
4.1 Spark 运行时架构
在分布式环境下,Spark 集群采用的是主 / 从结构。在一个 Spark 集群中,有一个节点负责中央协调,调度各个分布式工作节点。这个中央协调节点被称为驱动器(Driver)节点,与之对应的工作节点被称为执行器(executor)节点。驱动器节点可以和大量的执行器节点进行通信,它们也都作为独立的 Java 进程运行。驱动器节点和所有的执行器节点一起被称为一个 Spark 应用(application)。
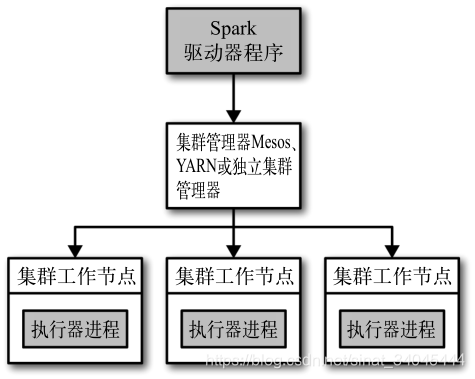
Spark 应用通过一个叫作集群管理器(Cluster Manager)的外部服务在集群中的机器上启动。Spark 自带的集群管理器被称为独立集群管理器。Spark 也能运行在 Hadoop YARN 和Apache Mesos 这两大开源集群管理器上。
4.2 Spark 集群搭建
4.2.1 集群搭建
1)、官网下载安装包:http://spark.apache.org/downloads.html,注意对应你的 Hadoop 版本;
2)、安装Spark tar;
3)、安装包根目录下conf文件夹,修改slaves.template文件,添加从节点:
[root@node01 conf] mv slaves.template slaves
[root@node01 conf] vim slaves
...
node02
node03
4)、修改spark-env.sh脚本,添加:
- Standalone Spark自带的集群管理器:
[root@node01 conf] mv spark-env.sh.template spark-env.sh
[root@node01 conf] vim spark-env.sh
...
JAVA_HOME=配置 java_home 路径
SPARK_MASTER_IP=master 的 ip
SPARK_MASTER_PORT=提交任务的端口,默认是 7077
SPARK_WORKER_CORES=每个 worker 从节点能够支配的 core 的个数
SPARK_WORKER_MEMORY=每个 worker 从节点能够支配的内存数
- Yarn 集群管理器,只需要在spark-env.sh中添加 hadoop 配置文件目录:
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
5)、测试集群
Spark 安装包自带 examples 样例 jar包,如:SparkPI 计算圆周率,Spark 1.6 版本位于:
S
P
A
R
K
H
O
M
E
/
l
i
b
/
文
件
夹
下
;
S
p
a
r
k
2.
x
版
本
位
于
:
SPARK_HOME/lib/ 文件夹下;Spark 2.x 版本位于:
SPARKHOME/lib/文件夹下;Spark2.x版本位于:SPARK_HOME/exampels/jars/ 文件夹下;
[root@node01 sbin] ./start-all.sh
[root@node01 bin] ./spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
[root@node01 bin] ./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
4.2.2 Master HA
Standalone 集群只有一个 Master,如果 Master 挂了就无法提交应用程序,需要给 Master 进行高可用配置,Master 的高可用可以使用fileSystem(文件系统)和 zookeeper(分布式协调服务)。
zookeeper 有选举和存储功能,可以存储 Master 的元素据信息,使用zookeeper 搭建的 Master 高可用,当 Master 挂掉时,备用的 Master会自动切换,推荐使用这种方式搭建 Master 的 HA。
4.2.3 Master 高可用搭建
1)、在 Spark Master 节点上配置主 Master,配置 spark-env.sh:
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node3:2181,node4:2181,node5:2181
-Dspark.deploy.zookeeper.dir=/sparkmaster0821"
2)、将该spark-env.sh文件发送到其它worker节点:
scp spark-env.sh node02:`pwd`
scp spark-env.sh node03:`pwd`
3)、找一台节点(非主 Master 节点)配置备用 Master,修改spark-env.sh 配置节点上的 MasterIP:
SPARK_MASTER_IP=node02
4)、启动集群之前启动 zookeeper 集群:
zkServer.sh start
5)、启动 spark Standalone 集群,在主master节点启动:
./start-all.sh
6)、启动备用master节点:
./start-master.sh
7)、打开主 Master 和备用 Master WebUI 页面,观察状态:主节点显示Status:ALIVE,备用节点显示Status:STANDBY。
注意:
- 主备切换过程中不能提交 Application。
- 提交任务时,需要同时指定主Master和备用Master:
./spark-submit --master spark://node01:7077,node02:7077 ......
4.3 Standalone 模式两种提交任务方式
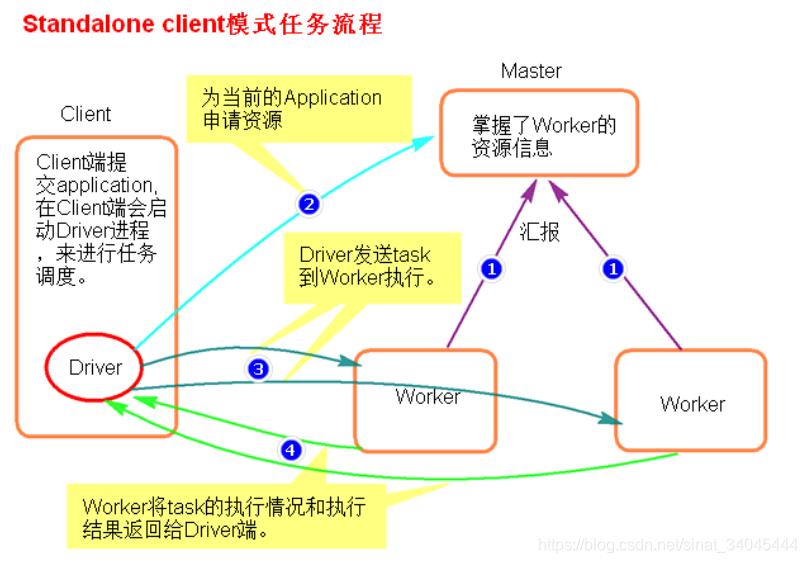
4.3.1 Standalone-client 提交提交任务方式
上一小节提交方式即为 client 提交方式:
[root@node01 bin] ./spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
或者:
[root@node01 bin] ./spark-submit --master spark://node01:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
执行流程:
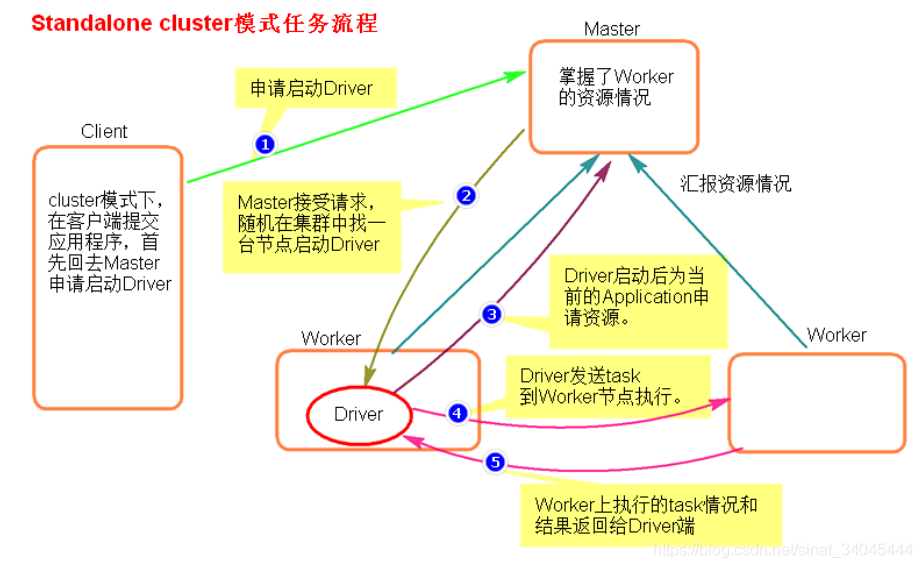
4.3.2 Standalone-cluster 提交任务方式
提交命令:
[root@node01 bin] ./spark-submit --master spark://node1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
注意:Standalone-cluster 提交方式,应用程序使用的所有 jar 包和文件,必须保证所有的 worker 节点都要有,因为此种方式,spark 不会自动上传包
执行流程:
4.4 Yarn 模式两种提交任务方式
4.4.1 yarn-client 提交任务
提交命令:
[root@node01 bin] ./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
或者:
[root@node01 bin] ./spark-submit --master yarn–client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
再或者:
[root@node01 bin] ./spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
执行流程:
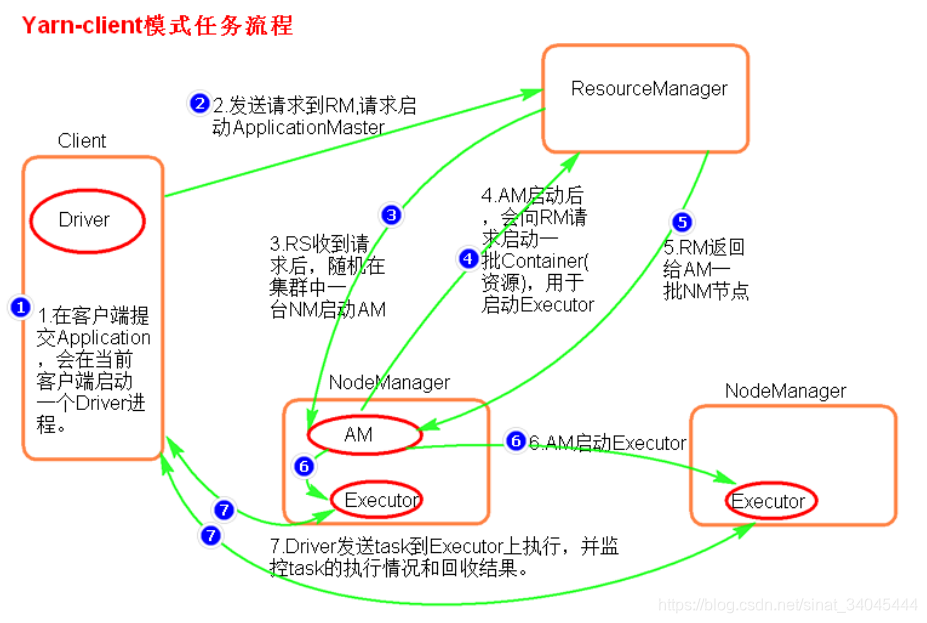
总结:Yarn-client 模式同样是适用于测试,因为 Driver 运行在本地,Driver会与 yarn 集群中的 Executor 进行大量的通信,会造成客户机网卡流量的大量增加。
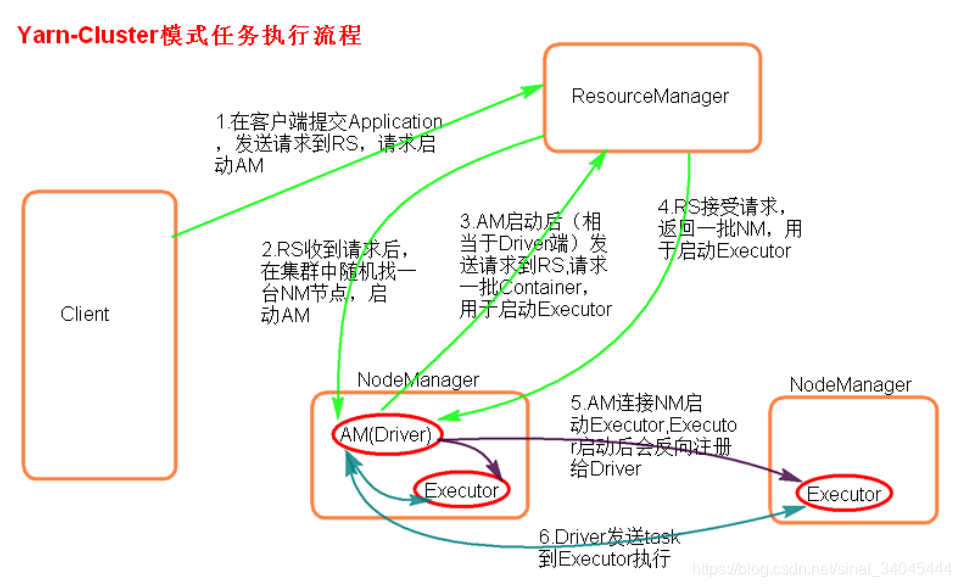
4.4.2 yarn-cluster提交任务
提交命令:
[root@node01 bin] ./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
或者:
[root@node01 bin] ./spark-submit --master yarn-cluster --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
执行流程:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)