6月25日,CVPR 2021 大会结束,共接收了 7039 篇有效投稿,最终有 1366 篇被接收为 poster,295 篇被接收为 oral,其中录用率大致为 23.6%,略高于去年的 22.1%。
CVPR 2021 全部接收论文列表:
https://openaccess.thecvf.com/CVPR2021?day=all
共分为33个大类,包含检测、分割、估计、跟踪、医学影像、文本、人脸、图像视频检索、三维视觉、图像处理等多个方向。Github项目地址:
https://github.com/extreme-assistant/CVPR2021-Paper-Code-Interpretation

论文一
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers(Oral)
标题:针对目标检测的无监督预训练Transformer
论文:https://arxiv.org/pdf/2011.09094.pdf
代码:https://github.com/dddzg/up-detr
利用Transformer做目标检测,DETR通过直截了当的编解码器架构,取得了引人注目的性能。受自然语言处理中预训练transformer语言模型的影响,本文提出了一个适用于目标检测的无监督预训练任务。具体而言,给定图片,我们随机的从其中裁剪下多个小补丁块输入解码器,将原来输入编码器,预训练任务要求模型从原图中找到随机裁剪的补丁块。在这个过程中,我们发现并解决了两个关键的问题:多任务学习和多个补丁块的定位。
(1)为了权衡预训练过程中,检测器对于分类和定位特征的偏好,我们固定了预训练的CNN特征并添加了一个特征重构的分支。
(2)为了同时支持多补丁定位,我们提出了注意力掩码和洗牌的机制。实验中,无监督预训练可以显著提升DETR在下游VOC和COCO上目标检测的性能。
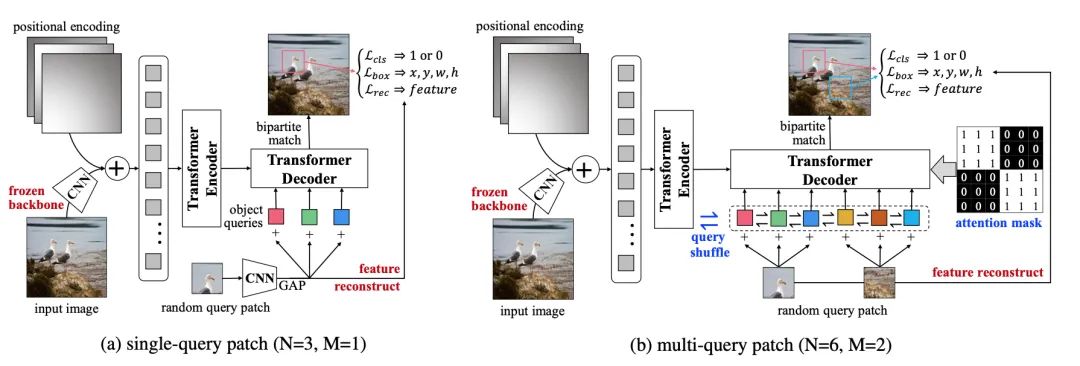
在今年4月,我们也邀请到了UP-DETR的论文一作戴志港来参加极市举办的主题为CVPR2021论文研讨会的线下沙龙,详细报告以及视频回放可以戳:极市沙龙回顾|CVPR2021-戴志港:UP-DETR,针对目标检测的无监督预训练Transformer。

论文二
Towards Open World Object Detection(Oral)
标题:开放世界中的目标检测
论文:https://arxiv.org/abs/2103.02603
代码:https://github.com/JosephKJ/OWOD
详细解读:目标检测一卷到底之后,终于有人为它挖了个新坑|CVPR2021 Oral
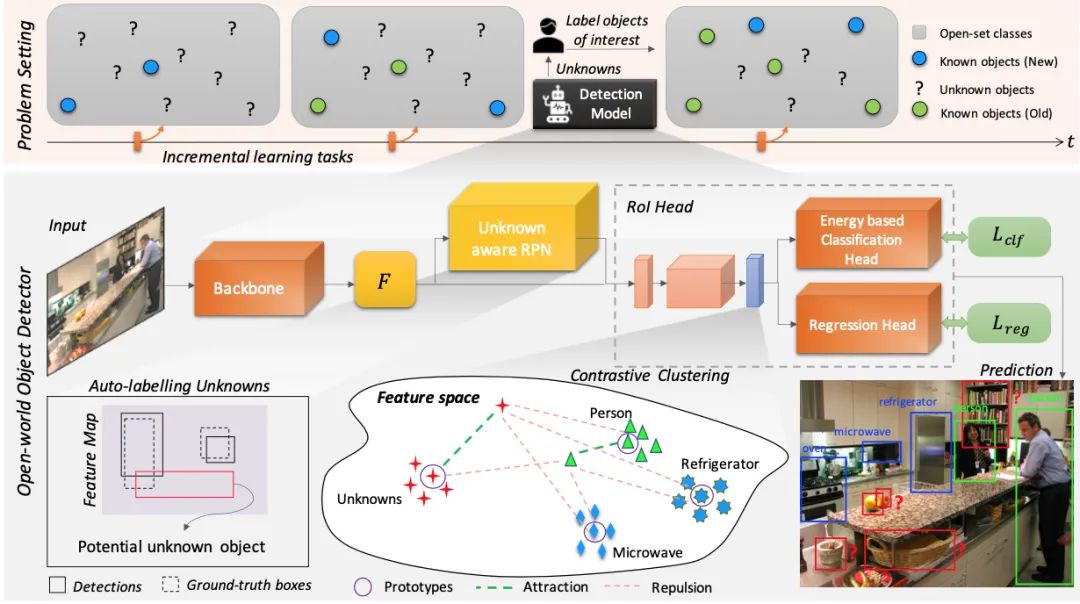
虽然目标检测技术目前已经发展得较为成熟,但如果要真正能实现让计算机像人眼一样进行识别,有项功能一直尚未达成——那就是像人一样能识别现实世界中的所有物体,并且能够逐渐学习认知新的未知物体。来本文发现并解决了这个问题。提出了一种新颖的方案:Open World Object Detector,简称ORE,即开放世界的目标检测。
ORE主要包含两个任务:
-
Open Set Learning,即在没有明确监督的情况下,将尚未引入的目标识别为“未知”;
-
Incremental Learning,即让网络进行N+1式增量学习,接收相应标签以学习其识别到的未知类别,同时不会忘记之前已经学到的类别。
论文三
You Only Look One-level Feature
标题:你只需要看一层特征
论文:https://arxiv.org/abs/2103.09460
代码:https://github.com/megvii-model/YOLOF
详细解读:我扔掉FPN来做目标检测,效果竟然这么强!YOLOF开源:你只需要看一层特征

本文对单阶段目标检测中的FPN进行了重思考并指出FPN的成功之处在于它对目标检测优化问题的分而治之解决思路而非多尺度特征融合。从优化的角度出发,作者引入了另一种方式替换复杂的特征金字塔来解决该优化问题:从而可以仅仅采用一级特征进行检测。基于所提简单而有效的解决方案,作者提出了YOLOF(You Only Look One-level Feature)。
YOLOF有两个关键性模块:Dilated Encoder与Uniform Matching,它们对最终的检测带来了显著的性能提升。COCO基准数据集的实验表明了所提YOLOF的有效性,YOLOF取得与RetinaNet-FPN同等的性能,同时快2.5倍;无需transformer层,YOLOF仅需一级特征即可取得与DETR相当的性能,同时训练时间少7倍。以大小的图像作为输入,YOLOF取得了44.3mAP的指标且推理速度为60fps@2080Ti,它比YOLOv4快13%。
本文的贡献主要包含以下几点:
-
FPN的关键在于针对稠密目标检测优化问题的“分而治之”解决思路,而非多尺度特征融合;
-
提出了一种简单而有效的无FPN的基线模型YOLOF,它包含两个关键成分(Dilated Encoder与Uniform Matching)以减轻与FPN的性能差异;
-
COCO数据集上的实验证明了所提方法每个成分的重要性,相比RetinaNet,DETR以及YOLOv4,所提方法取得相当的性能同时具有更快的推理速度。
论文四
End-to-End Object Detection with Fully Convolutional Network
标题:使用全卷积网络进行端到端目标检测
论文:https://arxiv.org/abs/2012.03544
代码:https://github.com/Megvii-BaseDetection/DeFCN
详细解读:丢弃Transformer,FCN也可以实现E2E检测

本文基于FCOS,首次在密集预测上利用全卷积结构做到E2E,即无NMS后处理。论文首先分析了常见的密集预测方法(如RetinaNet、FCOS、ATSS等),并且认为one-to-many的label assignment是依赖NMS的关键。受到DETR的启发,作者设计了一种prediction-aware one-to-one assignment方法。此外,还提出了3D Max Filtering以增强feature在local区域的表征能力,并提出用one-to-many auxiliary loss加速收敛。
本文方法基本不修改模型结构,不需要更长的训练时间,可以基于现有密集预测方法平滑过渡。在无NMS的情况下,在COCO数据集上达到了与有NMS的FCOS相当的性能;在代表了密集场景的CrowdHuman数据集上,论文方法的recall超越了依赖NMS方法的理论上限。
论文五
Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection
标题:学习可靠的定位质量估计用于密集目标检测
论文:https://arxiv.org/abs/2011.12885
代码:https://github.com/implus/GFocalV2
详细解读:大白话 Generalized Focal Loss V2,https://zhuanlan.zhihu.com/p/313684358

本文应该是检测领域首次引入用边界框的不确定性的统计量来高效地指导定位质量估计,从而基本无cost(包括在训练和测试阶段)地提升one-stage的检测器性能,涨幅在1~2个点AP。
论文六
Positive-Unlabeled Data Purification in the Wild for Object Detection
标题:野外目标检测的正无标注数据清洗
得益于大量标注图像,基于深度学习的目标检测方法取得了很大进展。然而,图像标注仍然是一个费力、耗时且容易出错的过程。为了进一步提高检测器的性能,本文寻求利用所有可用的标注数据并从野外的大量未标注图像中挖掘有用的样本,这在以前很少讨论。
本文提出了一种基于正未标注学习的方案,通过从大量未标注的图像中提纯有价值的图像来扩展训练数据,其中原始训练数据被视为正数据,而野外未标记的图像是未标记数据。为了有效地提纯这些数据,提出了一种基于提示学习和真实值有界知识蒸馏的自蒸馏算法。实验结果验证了所提出的正未标注数据提纯可以通过挖掘海量未标注数据来增强原始检测器。本文方法在 COCO 基准上将FPN 的 mAP 提高了 2.0%。
论文七
Multiple Instance Active Learning for Object Detection
标题:用于目标检测的多实例主动学习
代码:https://github.com/yuantn/MI-AOD
详细解读:MI-AOD: 少量样本实现高检测性能,https://zhuanlan.zhihu.com/p/362764637

尽管主动学习在图像识别方面取得了长足的进步,但仍然缺乏一种专门适用于目标检测的示例级的主动学习方法。本文提出了多示例主动目标检测(MI-AOD),通过观察示例级的不确定性来选择信息量最大的图像用于检测器的训练。MI-AOD定义了示例不确定性学习模块,该模块利用在已标注集上训练的两个对抗性示例分类器的差异来预测未标注集的示例不确定性。MI-AOD将未标注的图像视为示例包,并将图像中的特征锚视为示例,并通过以多示例学习(MIL)方式对示例重加权的方法来估计图像的不确定性。反复进行示例不确定性的学习和重加权有助于抑制噪声高的示例,来缩小示例不确定性和图像级不确定性之间的差距。实验证明,MI-AOD为示例级的主动学习设置了坚实的基线。在常用的目标检测数据集上,MI-AOD和最新方法相比具有明显的优势,尤其是在已标注集很小的情况下。
论文八
Instance Localization for Self-supervised Detection Pretraining
标题:自监督检测预训练的实例定位
论文:https://arxiv.org/abs/2102.08318
代码:https://github.com/limbo0000/InstanceLoc

先前对自监督学习的研究已经在图像分类方面取得了相当大的进步,但通常在目标检测方面的迁移性能下降。本文的目的是推进专门用于目标检测的自监督预训练模型。基于分类和检测之间的固有差异,我们提出了一种新的自监督前置任务,称为实例定位。图像实例粘贴在不同的位置并缩放到背景图像上。前置任务是在给定合成图像以及前景边界框的情况下预测实例类别。我们表明,将边界框集成到预训练中可以促进迁移学习的更好的任务对齐和架构对齐。此外,我们在边界框上提出了一种增强方法,以进一步增强特征对齐。因此,我们的模型在 ImageNet 语义分类方面变得更弱,但在图像定位方面变得更强,具有用于目标检测的整体更强的预训练模型。实验结果表明,我们的方法为 PASCAL VOC 和 MSCOCO 上的对象检测产生了最先进的迁移学习结果。
论文九
Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
标题:小样本目标检测的语义关系推理
论文:https://arxiv.org/abs/2103.01903
由于现实世界数据固有的长尾分布,小样本目标检测是一个必要且长期存在的问题。其性能在很大程度上受到新类数据稀缺性的影响。但是无论数据可用性如何,新类和基类之间的语义关系都是不变的。
在这项工作中,作者研究利用这种语义关系和视觉信息,并将显式关系推理引入新目标检测的学习中。具体来说,我们通过从大量文本语料库中学习到的语义嵌入来表示每个类概念。检测器被训练以将对象的图像表示投影到这个嵌入空间中。本文还确定了简单地使用带有启发式知识图的原始嵌入的问题,并建议使用动态关系图来增强嵌入。因此,SRR-FSD 的小样本检测器对新物体的镜头变化具有鲁棒性和稳定性。实验表明,SRR-FSD 可以在更高的镜头下获得有竞争力的结果,更重要的是,在较低的显式和隐式镜头下,性能明显更好。从预训练分类数据集中删除隐式镜头的基准协议可以作为未来研究的更现实的设置。
论文十
OPANAS: One-Shot Path Aggregation Network Architecture Search for Object Detection
标题:目标检测一键式路径聚合网络体系结构搜索
论文:https://arxiv.org/abs/2103.04507
代码:https://github.com/VDIGPKU/OPANAS
本文提出 OPANAS 算法,显著提高了搜索效率和检测精度,主要包含三个任务:
-
引入六种异构信息路径来构建搜索空间,即自上向下、自下向上、融合分裂、比例均衡、残差连接和无路径。
-
提出了一种新的 FPN 搜索空间,其中每个 FPN 候选者都由一个密集连接的有向无环图表示(每个节点是一个特征金字塔,每个边是六个异构信息路径之一)。
-
提出一种高效的一次性搜索方法来寻找最优路径聚合架构,即首先训练一个超网络,然后用进化算法找到最优候选者。
实验结果证明了所提出的 OPANAS 对目标检测的作用:(1)OPANAS 比最先进的方法更有效,搜索成本要小得多;(2) OPANAS 发现的最佳架构显著改进了主流检测器,mAP 提高了 2.3-3.2%;(3) 实现了最新的准确度与速度的均衡(52.2% mAP,7.6 FPS),训练成本比同类最先进技术更小。
论文十一
MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection
标题:用于类别感知无监督域自适应目标检测的内存引导注意力
论文:https://arxiv.org/abs/2103.04224
现有的无监督域自适应目标检测方法通过对抗性训练执行特征对齐。虽然这些方法在性能上实现了合理的改进,但它们通常执行与类别无关的域对齐,从而导致特征的负迁移。
本文尝试通过提出用于类别感知域适应的记忆引导注意(MeGA-CDA)来将类别信息纳入域适应过程。所提出的方法包括采用类别鉴别器来确保用于学习域不变鉴别特征的类别感知特征对齐。然而,由于目标样本的类别信息不可用,我们建议生成内存引导的特定类别注意图,然后用于将特征适当地路由到相应的类别鉴别器。所提出的方法在几个基准数据集上进行了评估,并且表现出优于现有方法。
论文十二
FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
标题:通过对比提案编码进行的小样本目标检测
论文:https://arxiv.org/abs/2103.05950v2
代码:https: //github.com/MegviiDetection/FSCE
本文提出的FSCE方法旨在从优化特征表示的角度去解决小样本物体检测问题。小样本物体检测任务中受限于目标样本的数目稀少,对目标样本的分类正确与否往往对最终的性能有很大的影响。FSCE借助对比学习的思想对相关候选框进行编码优化其特征表示,加强特征的类内紧凑和类间相斥,最后方法在常见的COCO和Pascal VOC数据集上都得到有效提升。
论文十三
Robust and Accurate Object Detection via Adversarial Learning
标题:通过对抗学习进行稳健而准确的目标检测
论文:https://arxiv.org/abs/2103.13886
模型:https://github.com/google/automl/tree/master/efficientdet/Det-AdvProp.md

数据增强已经成为训练高性能深度图像分类器的一个组成部分,但是它在目标检测方面的潜力尚未被充分挖掘。鉴于大多数最先进的目标检测器都得益于对预先训练好的分类器进行微调,本文首先研究了分类器从各种数据增强中获得的收益如何迁移至目标检测。但结果令人沮丧:在精度或鲁棒性方面,微调后增益减小。因而,本文通过探索对抗性的例子来增强目标检测器的微调阶段,可以看作是一种依赖于模型的数据增强。本文方法动态地选择来自检测器分类和定位分支的强对抗性图像,并随检测器迭代,以确保增强策略保持最新和相关。这种依赖于模型的增广策略比自动增广这样基于一个特定检测器的模型无关增广策略更适用于不同的目标检测器。
论文十四
I^3Net: Implicit Instance-Invariant Network for Adapting One-Stage Object Detectors
标题:用于适应一阶段目标检测器的隐式实例不变网络
论文:https://arxiv.org/abs/2103.13757

最近关于两阶段跨域检测的工作广泛地探索了局部特征模式,以获得更准确的自适应结果。这些方法在很大程度上依赖于区域建议机制和基于ROI的实例级特征来设计针对前景对象的细粒度特征对齐模块。然而,对于单级检测器,很难甚至不可能在检测管道中获得显式的实例级特征。基于此,我们提出了一种隐式实例不变网络(I3Net),该网络是为适应一级检测器而定制的,通过利用不同层次深层特征的自然特征隐式学习实例不变特征。本文从三个方面促进了自适应:
-
动态类平衡重加权(DCBR)策略,该策略考虑了域内和类内变量的共存,为样本稀缺和易于适应的样本分配更大的权重;
-
类别感知对象模式匹配(COPM)模块,在类别信息的引导下,增强跨域前景对象匹配,抑制非信息背景特征;
-
正则化联合类别对齐(RJCA)模块,通过一致性正则化在不同的领域特定层上联合执行类别对齐。
论文十五
Distilling Object Detectors via Decoupled Features
标题:利用解耦特征提取目标检测器
论文:https://arxiv.org/abs/2103.14475
代码:https://github.com/ggjy/DeFeat.pytorch
与图像分类不同,目标检测器具有复杂的多损失函数,其中语义信息所依赖的特征非常复杂。本文指出一种在现有方法中经常被忽略的路径:从不包括物体的区域中提取的特征信息对于提取学生检测器。同时阐明了在蒸馏过程中,不同区域的特征应具有不同的重要性。并为此提出了一种新的基于解耦特征(DeFeat)的提取算法来学习更好的学生检测器。具体来说,将处理两个层次的解耦特征来将有用信息嵌入到学生中,即来自颈部的解耦特征和来自分类头部的解耦建议。在不同主干的探测器上进行的大量实验表明,该方法能够超越现有的目标检测蒸馏方法。
论文十六
OTA: Optimal Transport Assignment for Object Detection
标题:目标检测的最优传输分配
论文:https://arxiv.org/abs/2103.14259
代码:https://github.com/Megvii-BaseDetection/OTA

本文提出了一种基于最优传输理论的目标检测样本匹配策略,利用全局信息来寻找最优样本匹配的结果,相对于现有的样本匹配技术,具有如下优势:
-
检测精度高。全局最优的匹配结果能帮助检测器以稳定高效的方式训练,最终在COCO数据集上达到最优检测性能。
-
适用场景广。现有的目标检测算法在遇到诸如目标密集或被严重遮挡等复杂场景时,需要重新设计策略或者调整参数,而最优传输模型在全局建模的过程中包括了寻找最优解的过程,不用做任何额外的调整,在各种目标密集、遮挡严重的场景下也能达到最先进的性能,具有很大的应用潜力。
论文十七
Data-Uncertainty Guided Multi-Phase Learning for Semi-Supervised Object Detection
标题:基于数据不确定性的多阶段学习半监督目标检测
论文:https://arxiv.org/abs/2103.16368
本文深入研究了半监督对象检测,其中利用未标注的图像来突破全监督对象检测模型的上限。以往基于伪标签的半监督方法受噪声影响严重,容易对噪声标签过拟合,无法很好地学习不同的未标记知识。为了解决这个问题,本文提出了一种用于半监督目标检测的数据不确定性引导的多阶段学习方法,根据它们的难度级别综合考虑不同类型的未标记图像,在不同阶段使用它们,并将不同阶段的集成模型一起生成最终结果。图像不确定性引导的简单数据选择和区域不确定性引导的 RoI 重新加权参与多阶段学习,使检测器能够专注于更确定的知识。
论文十八
Scale-aware Automatic Augmentation for Object Detection
标题:用于目标检测的尺度感知自动增强
论文:https://arxiv.org/abs/2103.17220
代码:https://github.com/Jia-Research-Lab/SA-AutoAug
本文提出了一种用于目标检测的数据增强策略,定义了一个新的尺度感知搜索空间,其中图像级和框级增强都旨在保持尺度不变性。在这个搜索空间上,本文提出了一种新的搜索指标,称为帕累托规模均衡(Pareto Scale Balance),以促进高效搜索。在实验中,即使与强大的多尺度训练基线相比,尺度感知自动增强对各种目标检测器(如 RetinaNet、Faster R-CNN、Mask R-CNN 和 FCOS)也产生了显著且一致的改进。本文搜索的增强策略可转移到目标检测之外的其他视觉任务(如实例分割和关键点估计)以提高性能,且搜索成本远低于以前用于目标检测的自动增强方法。
论文十九
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
标题:具有上下文感知聚合的密集关系蒸馏用于小样本目标检测
论文:https://arxiv.org/abs/2103.17115
代码:https://github.com/hzhupku/DCNet

传统的基于深度学习的目标检测方法需要大量的边界框标注进行训练,获得如此高质量的标注数据成本很高。小样本目标检测能通过少量带标注的样本学习新类,非常具有挑战性,因为新目标的细粒度特征很容易被忽略,而只有少数可用数据。
在这项工作中,为了充分利用带标注的新对象的特征并捕获查询对象的细粒度特征,作者提出了具有上下文感知聚合的密集关系蒸馏来解决小样本检测问题。密集关系蒸馏模块建立在基于元学习的框架之上,旨在充分利用支持特征,其中支持特征和查询特征密集匹配,以前馈方式覆盖所有空间位置。引导信息的大量使用让模型能处理常见挑战(例如外观变化和遮挡)。此外,为了更好地捕获尺度感知特征,上下文感知聚合模块自适应地利用来自不同尺度的特征以获得更全面的特征表示。
论文二十
DAP: Detection-Aware Pre-training with Weak Supervision
标题:弱监督下的检测感知预训练
论文:https://arxiv.org/abs/2103.16651
本文提出了一种检测感知预训练方法,该方法仅利用弱标记的分类样式数据集进行预训练,但专门为使目标检测任务受益而量身定制。与广泛使用的基于图像分类的预训练不同,它不包括任何与位置相关的训练任务,本文通过基于类激活图的弱监督对象定位方法将分类数据集转换为检测数据集,直接预训练检测器,使预先训练的模型具有位置感知能力并能够预测边界框。在下游检测任务中,DAP在效率和收敛速度方面都可以优于传统的分类预训练。特别是当下游任务中的样本数量很少时,DAP 可以大幅提高检测精度。
论文二十一
Adaptive Class Suppression Loss for Long-Tail Object Detection
标题:用于长尾目标检测的自适应类抑制损失
论文:https://arxiv.org/abs/2104.00885
代码:https://github.com/CASIA-IVA-Lab/ACSL
为了解决大词汇量目标检测任务的长尾分布问题,现有的方法通常将整个类别分为几组,并对每组采取不同的策略。这些方法带来以下两个问题一:一是大小相似的相邻类别之间的训练不一致,二是学习的模型对尾部类别缺乏区分,这些尾部类别在语义上与某些头部类别相似。
本文设计了一种新颖的自适应类别抑制损失(ACSL)来有效解决上述问题,并提长尾类别的检测性能。本文引入了一个无统计的视角来分析长尾分布,打破了手动分组的限制,因而 ACSL 能自适应地调整每个类别的样本的抑制梯度,确保训练的一致性,并提高对稀有类别的区分度。以ResNet50-FPN作为基准,ACSL 在长尾数据集 LVIS 和 Open Images 上分别实现了 5.18% 和 5.2% 的提升。
论文二十二
IQDet: Instance-wise Quality Distribution Sampling for Object Detection
标题:用于目标检测的实例质量分布采样 论文:https://arxiv.org/abs/2104.06936
0
本文提出了一种具有实例采样策略的密集对象检测器。与使用先验采样策略不同,本文首先提取了每个真值的区域特征来估计实例质量分布。根据空间维度的混合模型,该分布具有更强的抗噪性并适应每个实例的语义模式。基于分布,本文提出了一种质量采样策略,它以概率的方式自动选择训练样本,并用更多的高质量样本进行训练。在 MS COCO 上的大量实验表明,我们的方法简单稳定地提高了近 2.4 个 AP。本文最好的模型达到了 51.6 AP,优于所有现有的最先进的单阶段检测器,且在推理时间上完全无消耗。
论文二十三
Line Segment Detection Using Transformers without Edges(Oral)
标题:使用无边缘Transformer的线段检测
论文:https://arxiv.org/abs/2101.01909

本文提出了一种使用 Transformer 的联合端到端线段检测算法(LETR),该算法无需后处理和启发式引导的中间处理(边缘/结点/区域检测)。LETR通过跳过边缘元素检测和感知分组过程的标准启发式设计,利用了 Transformer 中集成的标记化查询、自注意力机制和编码解码策略。本文为 Transformers 配备了多尺度编码器/解码器策略,以在直接端点距离损失下执行细粒度线段检测。该损失项特别适用于检测几何结构,例如标准边界框不方便表示的线段。
论文二十四
Domain-Specific Suppression for Adaptive Object Detection
标题:自适应目标检测的特定领域抑制
论文:https://arxiv.org/abs/2105.03570

由于复杂任务对模型的可迁移性有更高要求,领域自适应方法在目标检测中面临性能下降的问题。当前的UDA目标检测方法在优化时将两个方向视为一个整体,即使输出特征完美对齐也会导致域不变方向不匹配。
本文对提升 CNN 可迁移性的新视角进行了探讨,将模型的权重视为一系列运动模式。权重的方向和梯度可以分为领域特定和领域不变的部分,领域适应的目标是专注于领域不变的方向,同时消除领域特定的干扰。
本文提出了特定领域的抑制,这是一种对反向传播中原始卷积梯度的示例性和可推广的约束,以分离方向的两个部分并抑制特定领域的方向。作者进一步验证了在几个域自适应对象检测任务上的理论分析和方法,包括天气、相机配置和合成到现实世界的适应。实验结果表明,在 UDA 对象检测领域,本文方法与目前最先进的方法相比取得了显著进步,在所有这些域适应场景中实现了 10.2∼12.2% mAP 的提升。
论文二十五
PSRR-MaxpoolNMS: Pyramid Shifted MaxpoolNMS with Relationship Recovery
标题:关系修复和金字塔移位MaxpoolNMS
论文:https://arxiv.org/abs/2105.12990
非极大值抑制 (NMS) 是现代卷积神经网络中用于目标检测的重要后处理步骤。与本质上并行的卷积不同,NMS 的实际标准 GreedyNMS 并不容易并行化,因而可能成为目标检测的性能瓶颈。MaxpoolNMS 被引入作为 GreedyNMS 的可并行替代方案,从而在不降低精度的条件下实现比 GreedyNMS 更快的速度。但是,MaxpoolNMS 只能在像 Faster-RCNN 这样的两阶段检测器的一阶段替换 GreedyNMS。在最终检测阶段应用 MaxpoolNMS 时,准确率会显著下降,因为 MaxpoolNMS 在边界框选择方面无法比拟 GreedyNMS。
本文提出了一种通用的、可并行的和可配置的方法 PSRR-MaxpoolNMS,以在所有检测器的所有阶段都能完全替代 GreedyNMS。通过引入简单的关系恢复模块和金字塔移位 MaxpoolNMS 模块,PSRR-MaxpoolNMS 能够比 MaxpoolNMS 更贴近 GreedyNMS。综合实验表明,本文方法在很大程度上优于 MaxpoolNMS,并且被证明比 GreedyNMS 更快且具有相当的准确性。PSRR-MaxpoolNMS 首次为定制化硬件设计提供了完全可并行化的解决方案,可重复用于加速各处的 NMS。
论文二十六
Improved Handling of Motion Blur in Online Object Detection
标题:改进在线目标检测中运动模糊的处理
论文:https://arxiv.org/abs/2011.14448
目标检测已经非常具有挑战性,当图像模糊时更难。大多数现有的努力要么集中在清晰的图像上,易于标记真值,要么将运动模糊视为通用损坏之一。而本文希望为将在现实世界中运行的在线视觉系统检测特定类别的对象。
本文特别关注自运动引起的模糊的细节。探索了五种解决方案,每一种都针对导致清晰和模糊图像之间性能差距的不同潜在原因。首先对图像进行去模糊处理,但目前只能部分改善目标检测。其他四类措施涉及多尺度纹理、分布外测试、标签生成和模糊类型调节。令人惊讶的是,作者发现能够解决空间歧义的自定义标签生成领先于其他所有方法,显著改善了目标检测。此外,与分类的结果相反,通过根据定制的运动模糊类别调节模型,本文方法取得了显著的性能提升。
论文二十七
Open-Vocabulary Object Detection Using Captions(Oral)
标题:使用字幕的开放词汇目标检测
论文:https://arxiv.org/abs/2011.10678
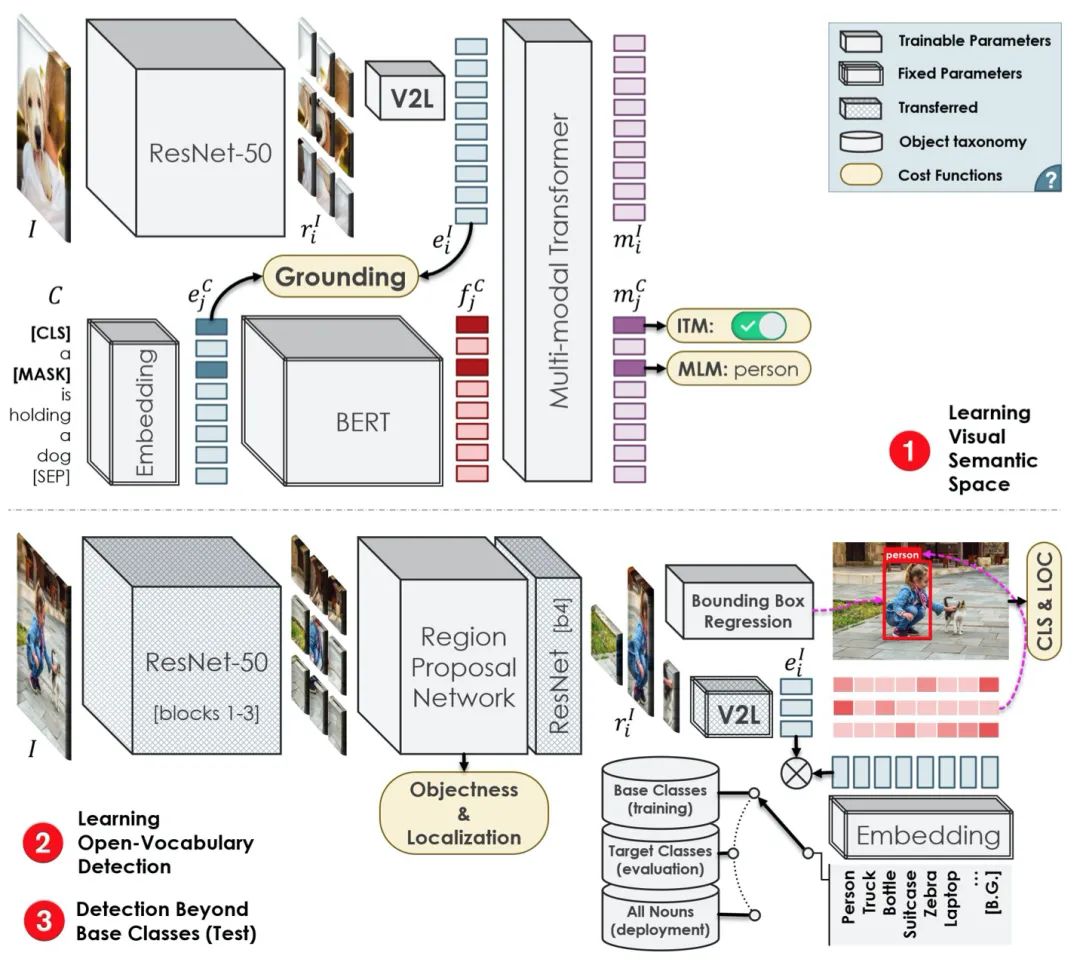
尽管深度神经网络在目标检测中具有非凡的准确性,但由于监督要求,它们的训练和扩展成本很高。特别是,学习更多的对象类别通常需要按比例增加更多的边界框注释。虽然已有工作探索了弱监督和零样本学习技术,以在监督较少的情况下将目标检测器扩展到更多类别,但它们并没有像监督模型那样成功和广泛采用。
本文提出了目标检测问题的一种新表述,即开放词汇目标检测,它比弱监督和零样本方法更通用、更实用、更有效。文章提出了一种新方法,为有限的一组对象类别用边界框注释来训练目标检测器,同时以显著更低的成本覆盖更多种类对象的图像-字幕对。本文所提出的方法可以检测和定位在训练期间未提供边界框注释的对象,其准确度明显高于零样本方法。同时,具有边界框注释的对象几乎可以与监督方法一样准确地被检测到,这明显优于弱监督基线。因此,我们为可扩展的对象检测建立了一种新的技术状态。