别看了 有错的 我懒得改了
强推https://www.bilibili.com/video/BV18J411a7yY?t=591
看完你还不会那我也没办法了
\
算法原理
模糊c-均值聚类算法 fuzzy c-means algorithm (FCMA)或称(FCM)。在众多模糊聚类算法中,模糊C-均值(FCM)算法应用最广泛且较成功,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属以达到自动对样本数据进行分类的目的。
先来讲讲这个算法的名字噢,什么叫Fuzzy,什么叫模糊呢,在经典的集合理论,一个元素是否属于集合,只有真或者假两种情况,也可以说只有0和1两种情况,0为假1为真。比如我们想要定义一个集合表示“年轻人”,那么我们需要设置一个阈值,当一个人的年龄小于这阈值的时候,就认为这个人属于这个集合,反之则不属于。假如用A表示年轻人这个集合,以20岁为阈值。则这个集合的隶属度函数可以表示如下:
μ
A
(
z
)
=
{
1
,
z
<
20
0
,
z
≥
20
\mu_A(z)= \begin{cases} 1, z < 20 \\ 0, z \geq 20 \end{cases}
μA(z)={1,z<200,z≥20
上面的公式可以用下面左图表示:
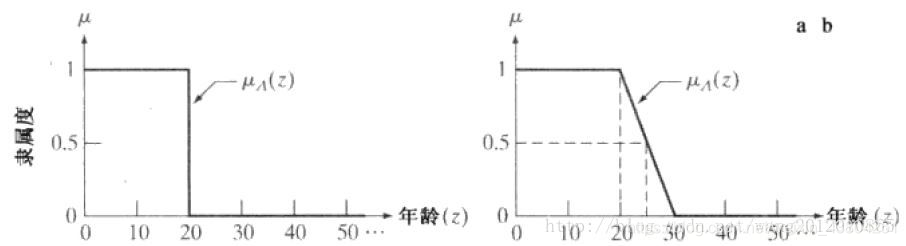
使用经典的集合理论,我们会面临着一些实际的问题,比如当一个人的年龄是20岁零1秒的时候,这个人就不再是年轻人了,这种粗暴的分类方式,在实际中并不实用。因此我们需要有过渡的函数来描述这个情况。上图中右边的图提供了一种解决方法,图中的斜线表示年龄的过渡。
于是就可以定义三个隶属度函数来确定年龄与三个模糊子集的关系:
μ
A
(
z
)
=
{
1
,
z
≤
20
30
−
z
10
,
20
<
z
<
30
0
,
z
≥
30
\mu_A(z)= \begin{cases} 1, z \leq 20 \\ \frac {30-z}{10}, 20< z < 30 \\ 0, z \geq 30 \end{cases}
μA(z)=⎩⎪⎨⎪⎧1,z≤201030−z,20<z<300,z≥30
OK,模糊的概念大概懂了,那么C-Means的C又是什么东西呢,额这个,好像没有什么含义,就像K-Means的k一样,只是代表聚类的个数,可能是cluster的c?又可能是模糊控制器(Fuzzy Controller)里的c。但是这个无关紧要,懂得模糊的概念就好了。
然后我们来正式说一下模糊c-均值是什么。模糊c-均值是一种允许一个数据属于一个或多个簇的方法,它不同于K-Means一个数据只能属于一个簇,它自发明以来广泛应用于模式识别中。
那么这种算法它的优化目标、目标函数是什么呢?看下面的公式:
m
i
n
J
m
=
∑
i
=
1
N
∑
j
=
1
C
μ
i
j
m
∣
∣
x
i
−
v
j
∣
∣
2
,
1
<
m
<
∞
s
.
t
.
∑
j
=
1
C
μ
i
j
=
1
(1)
min\ \ J_m=\sum_{i=1}^N \sum_{j=1}^C \mu_{ij}^m||x_i-v_j||^2, 1<m<\infty \tag1\\ s.t.\ \ \sum_{j=1}^C \mu_{ij}=1
min Jm=i=1∑Nj=1∑Cμijm∣∣xi−vj∣∣2,1<m<∞s.t. j=1∑Cμij=1(1)
符号定义:
N
:
N:
N: 是样本总个数
C
:
C:
C: 簇心数目,就是一开始输入的参数,你想这N个数据分成3份就将C置为3,5份就置为5,懂吧
μ
:
\mu:
μ: 一个
N
×
C
N\times C
N×C的矩阵,其中
μ
i
j
\mu_{ij}
μij是
x
i
x_i
xi属于类别
j
j
j的隶属度
v
j
:
v_j:
vj: 第
j
j
j个类别的中心
m
:
m:
m: 跟
C
C
C一样是自己设置的参数,不同的
m
m
m会有不同的聚类效果,需要根据不同的数据集进行调节
这个公式呢就是说每一个数据
x
i
x_i
xi到每一个聚类中心
v
j
v_j
vj距离的二范式再乘上
x
i
x_i
xi属于类别
j
j
j的隶属度的
m
m
m次方,要最小化它们的总和,直观一点就是希望每一个数据尽可能与它们所属的聚类中心接近。
那么就开始求如何使这个函数最小化了,(众所周知),求最小嘛,基本操作将它对某个变量求偏导,令偏导结果为零即可,因为有一个等式约束,我们先引入拉格朗日乘子
λ
\lambda
λ,于是原式可以写成:
m
i
n
J
=
∑
i
=
1
N
∑
j
=
1
C
μ
i
j
m
∣
∣
x
i
−
v
j
∣
∣
2
−
λ
(
∑
j
=
1
C
μ
i
j
−
1
)
(2)
min\ \ J=\sum_{i=1}^N \sum_{j=1}^C \mu_{ij}^m||x_i-v_j||^2 -\lambda(\sum_{j=1}^C \mu_{ij}-1) \tag2
min J=i=1∑Nj=1∑Cμijm∣∣xi−vj∣∣2−λ(j=1∑Cμij−1)(2)
然后对
λ
\lambda
λ求偏导并令其为零,得:
∂
J
∂
λ
=
∑
j
=
1
C
μ
i
j
−
1
=
0
(3)
\frac{\partial J}{\partial\lambda}=\sum_{j=1}^C \mu_{ij}-1=0 \tag3
∂λ∂J=j=1∑Cμij−1=0(3)
再对
μ
i
j
\mu_{ij}
μij求偏导并令其为零,得:
∂
J
∂
μ
i
j
=
m
⋅
μ
i
j
m
−
1
∣
∣
x
i
−
v
j
∣
∣
2
−
λ
=
0
(4)
\frac{\partial J}{\partial\mu_{ij}}=m\cdot \mu_{ij}^{m-1} ||x_i-v_j||^2 -\lambda=0 \tag4
∂μij∂J=m⋅μijm−1∣∣xi−vj∣∣2−λ=0(4)
由(4)可得
μ
i
j
=
(
λ
m
∣
∣
x
i
−
v
j
∣
∣
2
)
1
m
−
1
(5)
\mu_{ij}=\left( \frac{\lambda}{m||x_i-v_j||^2}\right)^\frac{1}{m-1} \tag5
μij=(m∣∣xi−vj∣∣2λ)m−11(5)
将(5)代入(3)得:
∑
j
=
1
C
(
λ
m
∣
∣
x
i
−
v
j
∣
∣
2
)
1
m
−
1
−
1
=
0
∑
j
=
1
C
(
λ
m
)
1
m
−
1
(
1
∣
∣
x
i
−
v
j
∣
∣
2
)
1
m
−
1
−
1
=
0
(
λ
m
)
1
m
−
1
∑
j
=
1
C
(
1
∣
∣
x
i
−
v
j
∣
∣
2
)
1
m
−
1
−
1
=
0
\begin{aligned} \sum_{j=1}^C \left( \frac{\lambda}{m||x_i-v_j||^2}\right)^\frac{1}{m-1}-1 &=0 \\ \sum_{j=1}^C \left( \frac{\lambda}{m}\right)^\frac{1}{m-1} \left( \frac1{||x_i-v_j||^2}\right)^\frac{1}{m-1}-1 &=0 \\ \left( \frac{\lambda}{m}\right)^\frac{1}{m-1}\sum_{j=1}^C \left( \frac1{||x_i-v_j||^2}\right)^\frac{1}{m-1}-1 &=0 \end{aligned}
j=1∑C(m∣∣xi−vj∣∣2λ)m−11−1j=1∑C(mλ)m−11(∣∣xi−vj∣∣21)m−11−1(mλ)m−11j=1∑C(∣∣xi−vj∣∣21)m−11−1=0=0=0
于是我们就可以得到:
(
λ
m
)
1
m
−
1
=
1
∑
j
=
1
C
(
1
∣
∣
x
i
−
v
j
∣
∣
2
)
1
m
−
1
(6)
\left( \frac{\lambda}{m}\right)^\frac{1}{m-1} =\frac1{\sum_{j=1}^C \left( \frac1{||x_i-v_j||^2}\right)^\frac{1}{m-1}} \tag6
(mλ)m−11=∑j=1C(∣∣xi−vj∣∣21)m−111(6)
将(6)再代入(4)得:
μ
i
j
=
1
∑
k
=
1
C
(
1
∣
∣
x
i
−
v
k
∣
∣
2
)
1
m
−
1
(
1
∣
∣
x
i
−
v
j
∣
∣
2
)
1
m
−
1
=
1
∑
k
=
1
C
(
∣
∣
x
i
−
v
j
∣
∣
2
∣
∣
x
i
−
v
k
∣
∣
2
)
1
m
−
1
(7)
\mu_{ij} = \frac1{\sum_{k=1}^C \left( \frac1{||x_i-v_k||^2}\right)^\frac{1}{m-1}} \left( \frac1{||x_i-v_j||^2}\right)^\frac{1}{m-1} = \frac1{\sum_{k=1}^C \left( \frac{||x_i-v_j||^2}{||x_i-v_k||^2}\right)^\frac{1}{m-1}} \tag7
μij=∑k=1C(∣∣xi−vk∣∣21)m−111(∣∣xi−vj∣∣21)m−11=∑k=1C(∣∣xi−vk∣∣2∣∣xi−vj∣∣2)m−111(7)
再对
v
i
v_i
vi求偏导并令其为零,得:
∂
J
∂
v
i
=
−
2
∑
i
=
1
N
μ
i
j
m
(
x
i
−
v
j
)
(8)
\frac{\partial J}{\partial v_i}=-2\sum_{i=1}^N\mu_{ij}^m(x_i-v_j) \tag8
∂vi∂J=−2i=1∑Nμijm(xi−vj)(8)
v
j
=
∑
i
=
1
N
μ
i
j
m
x
i
∑
i
=
1
N
μ
i
j
m
(9)
v_j=\frac{\sum_{i=1}^N\mu_{ij}^mx_i}{\sum_{i=1}^N\mu_{ij}^m}\tag9
vj=∑i=1Nμijm∑i=1Nμijmxi(9)
式(9)即为聚类中心
v
j
v_j
vj的更新公式。
总结一下模糊C均值的更新公式如下:
μ
i
j
=
1
∑
k
=
1
C
(
∣
∣
x
i
−
v
j
∣
∣
2
∣
∣
x
i
−
v
k
∣
∣
2
)
1
m
−
1
v
j
=
∑
i
=
1
N
μ
i
j
m
x
i
∑
i
=
1
N
μ
i
j
m
\mu_{ij}=\frac1{\sum_{k=1}^C \left( \frac{||x_i-v_j||^2}{||x_i-v_k||^2}\right)^\frac{1}{m-1}}\ \ \ \ \ \ \ \ v_j=\frac{\sum_{i=1}^N\mu_{ij}^mx_i}{\sum_{i=1}^N\mu_{ij}^m}
μij=∑k=1C(∣∣xi−vk∣∣2∣∣xi−vj∣∣2)m−111 vj=∑i=1Nμijm∑i=1Nμijmxi
算法步骤
- 确定类别数C,参数m,和迭代停止误差
ε
\varepsilon
ε以及最大迭代次数T
- 初始化聚类中心
V
=
{
v
1
,
v
2
,
.
.
.
,
v
C
}
V=\lbrace{v_1,v_2,...,v_C\rbrace}
V={v1,v2,...,vC}
- For t=1 to T:
Calculate
U
t
U_t
Ut with
V
t
−
1
V_{t-1}
Vt−1 and (7)
Calculate
V
t
V_t
Vt with
U
t
U_t
Ut and (9)
If
E
t
=
∣
∣
V
t
−
V
t
−
1
∣
∣
e
r
r
≤
ε
E_t=||V_t-V_{t-1}||_{err} \leq \varepsilon
Et=∣∣Vt−Vt−1∣∣err≤ε
Stop and put
(
U
f
,
V
f
)
=
(
U
t
,
V
t
)
(U_f, V_f)=(U_t, V_t)
(Uf,Vf)=(Ut,Vt); Else
Next t
举个例子
我们考虑FCM在一维下应用的情况。 使用二十个数据和三个聚类来初始化算法并计算U矩阵。 下图显示了每个基准面和每个聚类的成员隶属度。 根据隶属函数,数据的颜色是最近的群集的颜色。
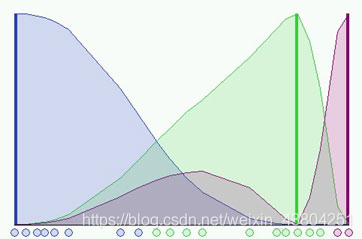
在上图所示的仿真中,我们使用了模糊系数
m
=
2
m = 2
m=2,其中模糊分布取决于簇的特定位置。 因为尚未执行任何步骤,所以无法很好地识别群集。 现在可以运行算法,直到验证停止条件为止。 下图显示了在第8步达到的最终条件,其中
m
=
2
m = 2
m=2 和
ε
=
0.3
\varepsilon= 0.3
ε=0.3:
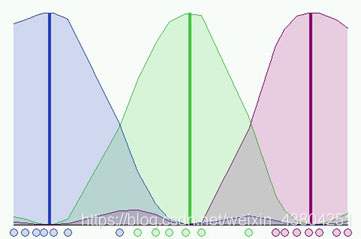
不同的初始化会导致算法的不同演化,它们可以收敛到相同的结果,但是迭代步骤的数量就不一样了。
python实现FCM对iris数据集进行聚类
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import scipy.io as scio
C = 3
m = 2
colors = ['r', 'b', 'g']
def norm2(x):
x = np.mat(x)
return np.dot(x.reshape(1, -1), x.reshape(-1, 1))
def cal(x_i, c_j, c_k):
x_i = np.mat(x_i).reshape(1, -1)
c_j = np.mat(c_j).reshape(1, -1)
c_k = np.mat(c_k).reshape(1, -1)
return float(np.power(norm2(x_i-c_j)/norm2(x_i-c_k), 2.0/(m-1)))
def fuzzy_c_means(data, m, C, EPS, T):
data = np.mat(data)
n, p = data.shape
V = [np.random.random([1, p]) for _ in range(C)]
U = [[0 for i in range(C)] for j in range(n)]
for i in range(n):
for j in range(C):
down = 0
for k in range(C):
down += cal(data[i], V[j], V[k])
U[i][j] = 1.0/down
for _ in range(T):
for j in range(C):
down = 0
V[j] = np.zeros([1, p])
for i in range(n):
u_i_j_m = pow(U[i][j], m)
V[j] += data[i]*u_i_j_m
down += u_i_j_m
V[j] /= down
upgrade = 0
for i in range(n):
for j in range(C):
down = 0
for k in range(C):
down += cal(data[i], V[j], V[k])
tmp = 1.0 / down
upgrade += abs(U[i][j]-tmp)
U[i][j] = tmp
if upgrade < EPS:
break
for i in range(n):
idx = np.argmax(U[i])
plt.scatter(float(data[i][:, 0]), float(data[i][:, 1]), c=colors[idx])
plt.show()
if __name__ == '__main__':
a = datasets.load_iris()
data = a['data']
pca = PCA(n_components=2)
data = pca.fit_transform(data)
fuzzy_c_means(data=data, m=2, C=C, EPS=1e-7, T=5000)
原数据通过PCA降到二维空间中的分布情况如下图所示
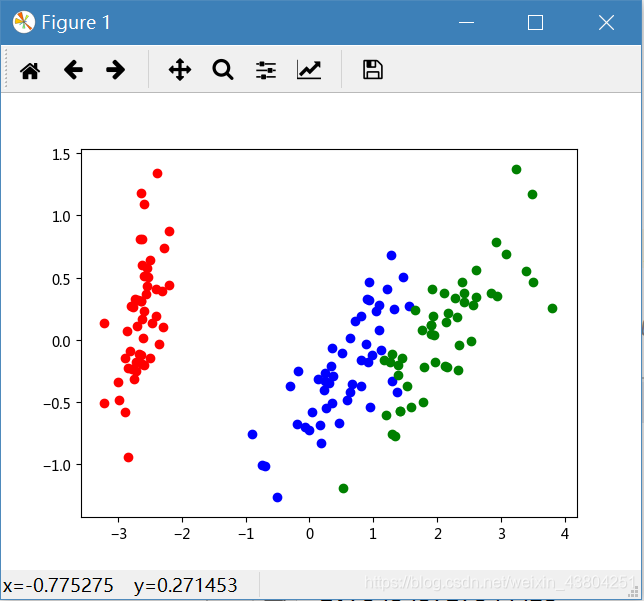
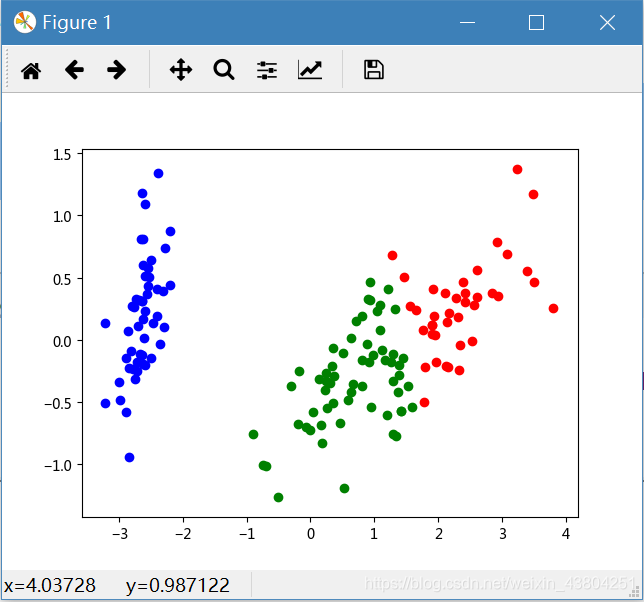
通过FCM进行聚类后的结果如下图所示
参考博客
http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/cmeans.html
https://blog.csdn.net/einsdrw/article/details/37930331
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)