YOLOv8实操:环境配置/自定义数据集准备/模型训练/预测
- 引言
- 1 环境配置
- 2 数据集准备
- 3 模型训练
- 4 模型预测
引言
源码链接:https://github.com/ultralytics/ultralytics
yolov8和yolov5是同一作者,相比yolov5,yolov8的集成性更好了,更加面向用户了
YOLO命令行界面(command line interface, CLI) 方便在各种任务和版本上训练、验证或推断模型。CLI不需要定制或代码,可以使用yolo命令从终端运行所有任务。
如果想了解yolo系列的更新迭代,以及yolov8的模型结构,推荐下面的链接:
YOLOv8详解 【网络结构+代码+实操】
笔者直接从实操入手
1 环境配置
安装pytorch、torchvision和其他依赖库
环境配置部分可以参考笔者的博客
【YOLO】YOLOv5-6.0环境搭建(不定时更新)
安装ultralytics
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e .
2 数据集准备
针对检测的数据集准备可以参考笔者的博客,这里不再赘述了
【YOLO】训练自己的数据集
3 模型训练
比起YOLOv5,YOLOv8的训练封装性更好了,有利有弊吧,参数默认值修改比较麻烦
训练指令如下:
yolo task=detect mode=train model=yolov8s.pt data=/media/ll/L/llr/DATASET/subwayDatasets/coco.yaml device=0 cache=True epochs=300 project=/media/ll/L/llr/mode name=yolov8
除了上述笔者使用的参数,其他参数说明
task: detect
mode: train
model:
data:
epochs: 300
patience: 50
batch: 16
imgsz: 640
save: True
save_period: -1
cache: True
device:
workers: 8
project: /media/ll/L/llr/model
name: yolov8
exist_ok: False
pretrained: False
optimizer: SGD
verbose: True
seed: 0
deterministic: True
single_cls: False
image_weights: False
rect: False
cos_lr: False
close_mosaic: 10
resume: False
min_memory: False
overlap_mask: True
mask_ratio: 4
dropout: 0.0
val: True
split: val
save_json: False
save_hybrid: False
conf:
iou: 0.7
max_det: 300
half: False
dnn: False
plots: True
source:
show: False
save_txt: False
save_conf: False
save_crop: False
hide_labels: False
hide_conf: False
vid_stride: 1
line_thickness: 3
visualize: False
augment: False
agnostic_nms: False
classes:
retina_masks: False
boxes: True
format: torchscript
keras: False
optimize: False
int8: False
dynamic: False
simplify: False
opset:
workspace: 4
nms: False
lr0: 0.01
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 7.5
cls: 0.5
dfl: 1.5
fl_gamma: 0.0
label_smoothing: 0.0
nbs: 64
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
mosaic: 1.0
mixup: 0.0
copy_paste: 0.0
cfg:
v5loader: False
4 模型预测
weight_path = "best.pt"
imgdir = r'/media/ll/L/llr/DATASET/subwayDatasets/bjdt/images'
img_path = r'/media/ll/L/llr/DATASET/subwayDatasets/bjdt/images/L_0000018.jpg'
model = YOLO(weight_path)
results = model(img_path,show=False,save=False)
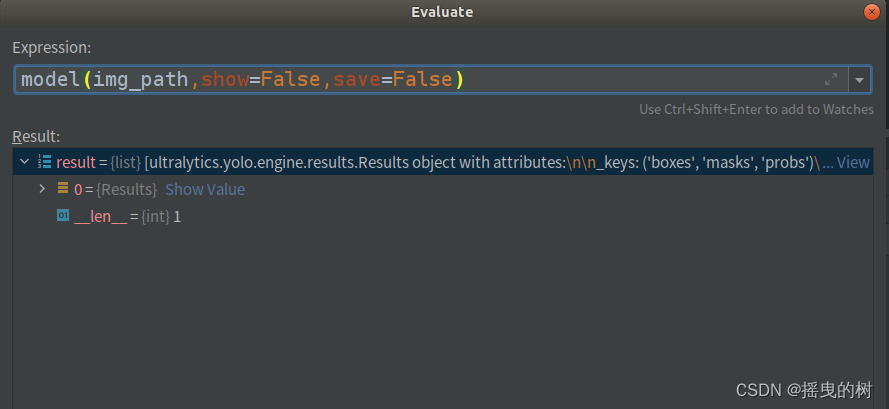
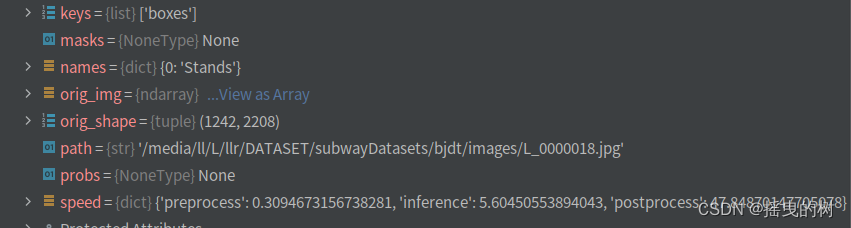
预测一张图片,results如下图所示:
预测文件夹目录,results如图所示:
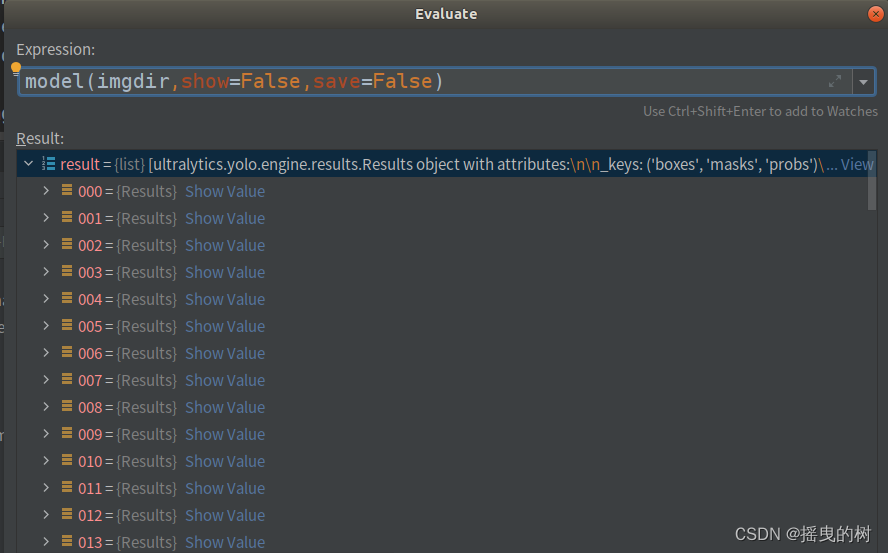
无论是一张图片还是图片目录,返回的results都是list
要对预测结果进行处理需要索引进去,如下图所示
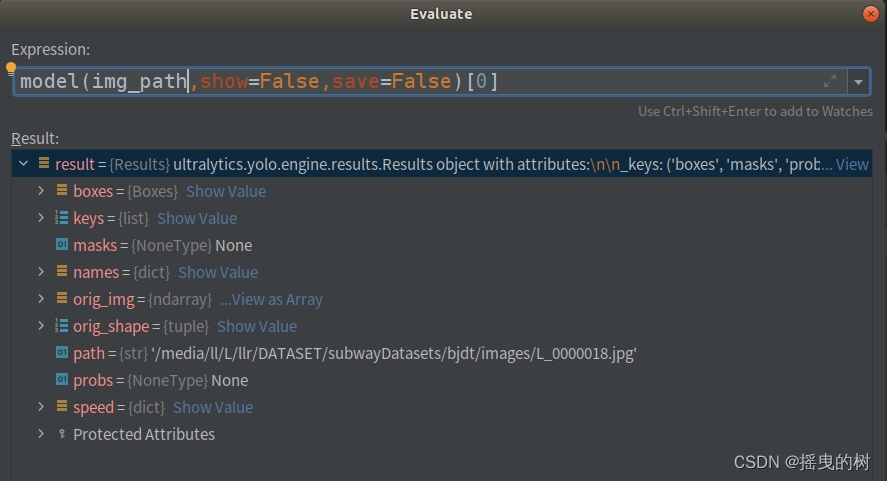
结果参数说明:
boxes:各种形式的检测框信息(xyxy、xywh、归一化的)、类别索引、置信度等
names:类别字典
orig_img:原图数组
orig_shape:原图尺寸
plots:在验证时保存图像(预测时一般为None)
speed:处理速度
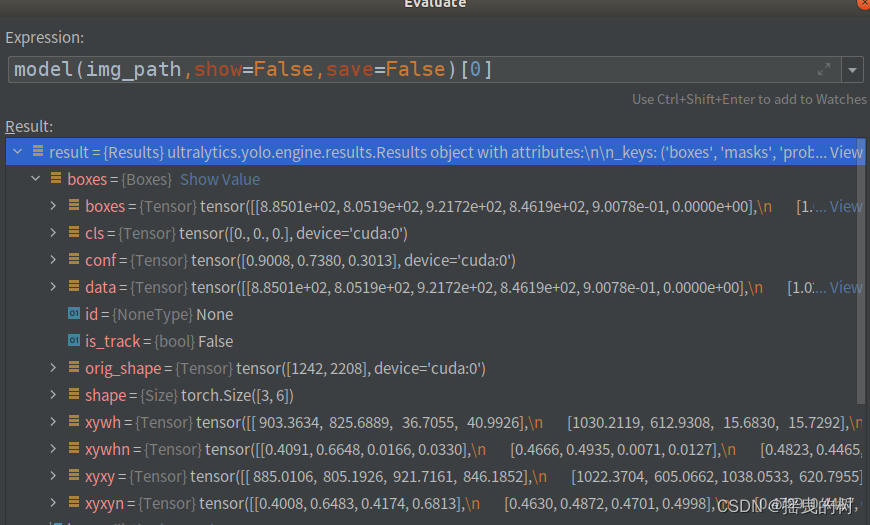
基于上述模型提供的检测结果进行后处理算法等
上述即为yolov8的快速使用
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)